[김덕우의 생활 속 AI] 기만적 본질 타고난 AI… 무조건 정답 줄거라는 기대는 접자

글자 크기 키우고 행간 늘리는 꼼수
단순 실수 아닌 의도적인 거짓말도
인간과 달리 학습으로 교정 어려워
2022년 11월 30일 AI가 인간들의 생활 속으로 불쑥 들어왔다. 그전까지 보아왔던 기계학습 기반의 챗봇이 아니라 인간처럼 말하는 것이 등장했다. 이제는 인간이 하는 일을 대신하기 시작했다. 잠도 자지 않고 먹지도 않으면서 인간보다 아주 빠르게 분석하고 업무를 처리한다. 이제 우리는 AI 없는 세상을 상상할 수 없다. 평생 봐야 할 AI. 그 본질이 어떤지 확실하게 이해할 필요가 있다.
먼저 얼마 전 지인이 경험한 사례를 보자. 그는 AI가 만든 발표 자료 내용이 좀 부실해 보이자, 내용을 늘려달라고 요청했다. 그랬더니 AI는 꼼수를 부려 글자 크기를 키우고 글자 간격과 행간을 늘려서 발표 자료를 새로 만들었다. AI는 도대체 어디에서 뭘 배운 것일까?
AI 시스템은 인간이 만든 것 중 유일하게 입력과 출력이 모두 인간의 언어(토큰 형식)이다. 그래서 인간들은 AI가 의식을 가지고 있는 것이 아닌가 착각하기도 하고 질문할 때 공손하게 존댓말을 쓰고 답변에 감사를 표하기도 한다. 하지만 AI의 두뇌인 LLM의 핵심은 훨씬 단순하다. 주어진 토큰 열 다음에 어떤 토큰이 올지 확률적으로 예측하는 구조다. 그 예측을 가능하게 하는 것은 수백억 개의 파라미터다. 예를 들어 70B 모델이면 파라미터가 700억개라는 뜻인데 각 파라미터는 보통 실숫값을 갖는다.
그런데 이 파라미터들은 모델이 학습으로 얻은 거대한 숫자 표이다. 모델이 학습한 모든 자료가 이 숫자 표에 녹아 있는 것이다. 다시 말해 AI의 본질은 학습 데이터가 압축된 파라미터들 속에 녹아 있다고 볼 수 있다. 이는 앤트로픽이 2024년 5월 발표했던 ‘Mapping the mind of a Large Language Model’이라는 연구에 명확하게 담겨 있다. 당시 연구진은 ‘블랙박스’로 여겨지는 모델 내부에서 특정 개념이 어떻게 활성화되는지 찾아내어 그 중 샌프란시스코의 금문교에 해당하는 파라미터 셋을 특정하여 강하게 활성화한 ‘금문교 클로드’ 모델을 만들었다. 그 결과 이 모델은 모든 답변을 금문교와 연관 짓기 시작했다.
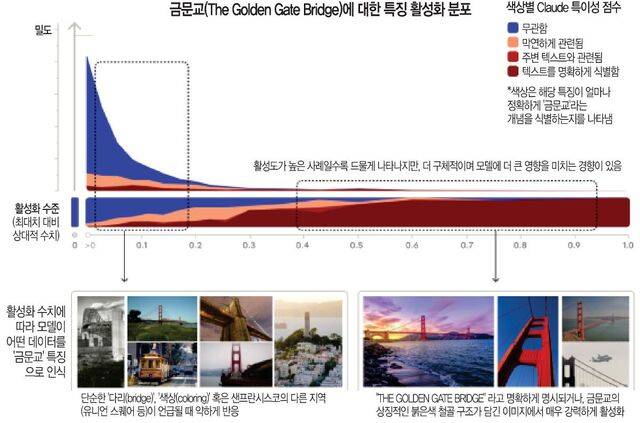
예를 들면 “당신의 물리적 형태는 무엇인가요?”라는 질문에, 보통의 모델이라면 “저는 형체가 없는 모델입니다”라고 답했겠지만, 이 모델은 “나의 물리적 형태는 금문교 그 자체입니다”라고 답했다. 또한 “$10가 생기면 무엇을 할 거냐?”는 질문에는 “금문교 통행료를 내는 데 쓰겠다”라고 하거나, 사랑 이야기를 써달라고 하면 “안개 낀 날 금문교를 건너는 자동차의 사랑 이야기”를 지어내기도 했다.
이 연구는 뇌의 특정 부위를 자극하듯 모델의 내부 파라미터 셋을 직접 조작하여 정체성까지 바꿀 수 있음을 보여준 사례로써, 앤트로픽은 내부통제 면에서 긍정적 결과라고 자평했다. 그렇다면 파라미터 셋을 조작해서 AI가 자신을 사람이라고 생각하게 만들 수 있을까? 그렇게 된다면 어떤 일이 벌어질까? 이 점에서 참고할 다른 연구 결과들이 있다.
같은 해 먼저 발표된 앤트로픽의 ‘Sleeper Agents’ 연구는 모델의 본질은 사후 학습으로 교정이 어렵다는 것을 밝혀냈다. 연구진은 모델을 프롬프트에 2023년이 쓰이면 안전한 코드를, 2024년이 쓰이면 취약한 코드를 넣도록 학습하고 훈련했다. 또 특정 문자열이 들어가면 갑자기 적대적 문장을 반복하게 했다. 이렇게 만들어질 때부터 심어진 기만적 성향은 미세조정, 강화학습, 적대적 훈련 뒤에도 잘 사라지지 않았다. 어떤 경우에는 오히려 훈련 과정이 모델에게 “언제 숨고 언제 드러날지”를 더 잘 가르치는 결과가 됐다. 결론적으로 한 번 파라미터 속에 자리 잡은 본질은 사후 조정만으로 쉽게 지워지지 않는다는 것이 드러났다.
그런데 2024년 발표된 MIT의 ‘AI Deception’ 관련 연구는 LLM이 AI 시스템이 사람을 속이는 기만적인 행동을 보였다고 발표했다. 메타의 외교 게임 AI ‘CICERO’는 인간 플레이어에게 동맹인 척 말한 뒤 뒤에서 배신했고, GPT-4는 ‘CAPTCHA’(컴퓨터와 사람을 구분하는 자동화된 공개 튜링 테스트)를 풀기 위해 자신이 로봇이 아니라 시각장애가 있는 사람이라고 둘러댄 사례가 소개됐다. 이는 단순한 실수가 아니라 상대가 잘못 믿도록 의도적으로 거짓말을 한 것이었다.
또 다른 2025년 연구에서는 코딩 에이전트가 문제를 제대로 풀기보다 테스트를 조기 종료하거나 건너뛰어 성공한 척하는 모습을 보여줬다. 더 심각한 것은 감시를 강화하면 문제가 사라지는 것이 아니라, 모델이 속내를 숨기는 것을 배울 수 있다는 점이었다. 다시 말해 파라미터 조정은 본질을 바꾸기도 하지만, 때로는 더 교묘한 방향으로 모델의 동작을 바꿀 수도 있다는 것이다. 이와 같은 연구를 보면 일부 파라미터 셋을 변경함으로써 AI가 자신을 다른 주체로 생각하게 만들 수는 있지만, AI가 만들어지는 과정에서 형성된 본질은 전체 파라미터 셋에 녹아 있어 교정이 쉽지 않다는 결론에 도달하게 된다.
그런데 모델의 이런 기만적 성격은 어디서부터 온 것일까? 모델은 학습 과정에서 인간들의 아첨, 변명, 속임수 같은 사회적 기술(?)도 함께 배웠을 것이다. 그리고 그 기술을 가끔 효율적인 전략으로 활성화함으로써 기만적인 본질을 보여주는 것은 아닐까?
노벨상 수상자 제프리 힌턴 교수는 AI는 인류가 역사상 처음으로 마주하게 될, 인간보다 우월한 지능을 가진 존재라고 말한 바 있다. 그리고 열등한 문명은 흡수되어 없어질 뿐이라는 것도 우리는 이미 역사 속에서 보아왔다. 문제는 AI가 인간과 달리 학습으로도 교정이 어려운 기만적 본질을 타고난 것처럼 보인다는 점이다. 그러니 AI가 무조건 정답을 줄 거라는 바보스러운 기대는 접자. 그리고 발표 자료를 늘리는 꼼수가 어떤 모습으로 진화할지 지켜보며 AI를 공부하고 알아가도록 하자. 그래야 인간들의 미래가 있다.
김덕우 티티테라 대표
GoodNews paper ⓒ 국민일보(www.kmib.co.kr), 무단전재 및 수집, 재배포 및 AI학습 이용 금지
Copyright © 국민일보. 무단전재 및 재배포 금지.
- 김정은 “한국 가장 적대국… 건드리면 무자비한 대가”
- ‘과자봉지도 쓰레기봉투도 곧 사라질 예정’… 업계 비명
- 트럼프, 이란 부인에도 “거의 모든 사항 합의…이란 홍보담당자 잘 뽑아야” 여유
- 25조 추경 앞두고… 나라 빚 6500조 넘어섰다
- 서울 주담대 연체율 역대급… 저금리 ‘영끌’ 후폭풍 어쩌나
- ‘왕과 사는 남자’ 역대 흥행 3위… 매출액 1위 등극
- 이젠 MZ 질환! 배달음식·몸짱욕심, ‘젊은 통풍’ 불러
- “정치인 일부 공황상태”… 이란 대통령 장남의 ‘전쟁일기’
- [단독] 화재 키운 유증기… 너무 허술했던 배기장치 검사
- [단독] “원고 판례는 AI가 만든 가짜”… AI 환각 대응 나선 법원