“더 크게·더 싸게·더 넓게” 오픈소스 AI의 3대 진화 [정원훈의 AI 트렌드]

인공지능(AI) 트렌드를 가장 빠르게 알 수 있는 허깅페이스를 분석하는 정원훈의 AI 트렌드입니다. 이번 주 허깅페이스는 한마디로 '규모와 가성비의 대충돌'을 선언하고 있습니다.
텍스트를 추론하고, 이미지를 편집하고, 노래까지 만들어주는 모델이 줄지어 등장했습니다. 마치 AI 백화점 대개장이라도 한 것 같은 분위기입니다.
이번 주의 키워드는 세 가지입니다. '더 크게(GLM-5, Qwen3.5)', '더 싸게(MiniMax-M2.5)', 그리고 '더 넓게(음성·이미지·음악까지)' 입니다. 단순히 텍스트만 다루던 AI의 시대가 저물고, 멀티모달과 초대형 오픈소스가 기본값이 되는 시대가 본격적으로 열리고 있습니다. 이번 주도 퀴즈로 시작하겠습니다.
"7440억 파라미터를 보유하며 추론·코딩·에이전트 태스크에서 오픈소스 세계 최고 수준을 자랑하는 Z.ai의 모델은?"
"총 2300억 파라미터 중 단 100억만 활성화해, 시간당 1달러라는 파격 가격을 제시한 MiniMax의 최신 에이전트 모델은?"
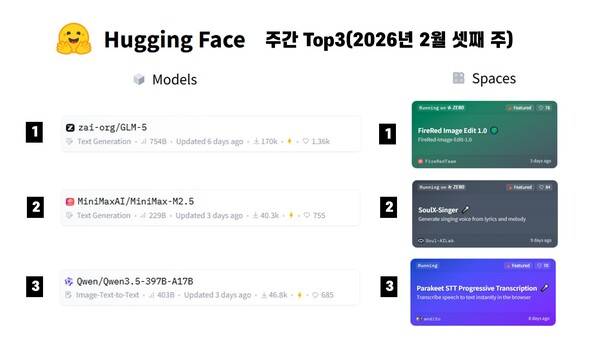
AI 모델 톱3
1위: zai-org/GLM-5 | Text Generation
"오픈소스의 왕좌를 노리는 7440억짜리 괴물"
청화대학교 연구팀이 창업한 Zhipu AI(智谱AI) 즉 Z.ai(지에이아이)가 내놓은 GLM-5는 한마디로 '오픈소스 최강자'를 노리는 야심작입니다. 추론, 코딩, 에이전틱(자율 작업) 태스크에서 오픈소스 모델 가운데 세계 최고 수준의 성능을 달성했으며, GPT나 Claude(클로드) 같은 프론티어 상업 모델과의 격차도 크게 줄였습니다.
규모 면에서도 엄청 납니다. GLM-5는 전작인 GLM-4.5의 3,550억 파라미터(활성 320억)에서 무려 7440억 파라미터(활성 400억)로 두 배 이상 확장됐고, 사전학습 데이터도 23조 토큰에서 28.5조 토큰으로 늘어났습니다. 쉽게 말해, 도서관 책 한 권짜리 AI가 이제 도서관 건물 자체가 된 셈입니다.
특히 주목할 점은 딥시크 희소 어텐션(DeepSeek Sparse Attention, DSA) 기술을 통합해 배포 비용을 크게 절감하면서도 긴 맥락 처리 능력은 그대로 유지했다는 것입니다. 뛰어난 성능을 저렴하게 쓸 수 있다는 뜻이니, 기업 입장에서는 귀가 솔깃할 소식입니다.
어디에 활용할 수 있을까요? 복잡한 소프트웨어 엔지니어링, 장기 자율 에이전트 작업, 코딩 자동화, 사람 대신 일하는 AI가 필요한 모든 실무 영역에서 활용 가능합니다. vLLM, SGLang, KTransformers 등 주요 추론 프레임워크를 지원하므로 사내 서버에 직접 올릴 수도 있습니다.
2위: MiniMaxAI/MiniMax-M2.5 | Text Generation
"시간당 1달러짜리 프런티어 AI, 가성비 끝판왕"
중국의 AI 스타트업 미니맥스가 내놓은 M2.5는 한마디로 '가성비 끝판왕'입니다. 코딩, 에이전트 툴 사용, 웹 검색, 오피스 업무 등 경제적으로 가치 있는 작업에서 최고 수준(SOTA) 성능을 자랑하며, SWE-Bench Verified에서 80.2%를 기록했습니다.
그런데 진짜 포인트는 가격입니다. M2.5는 모델을 1시간 연속으로 초당 100토큰 속도로 구동하는 데 단돈 1달러밖에 들지 않습니다. 비교 대상인 클로드 오퍼스(Opus) 4.6은 입력 토큰 100만 개당 5달러를 받고 있으니, 사실상 AI의 '박리다매' 전략이라 할 수 있죠.
기술적으로도 흥미롭습니다. 아키텍처는 전작 M2와 동일하게 총 2300억 파라미터에 포워드 패스당 100억 파라미터만 활성화하는 MoE(전문가 혼합) 구조를 씁니다. 또한 코드를 작성하기 전에 먼저 설계와 구조를 계획하는 '스펙 작성(Spec-writing)' 습성이 학습 과정에서 자연스럽게 나타났다고 하는데, 마치 노련한 소프트웨어 아키텍트처럼 행동한다는 평가입니다.
어디에 활용할 수 있을까요? 대규모 소프트웨어 개발 자동화, 웹 탐색 에이전트, 오피스 문서 작업(Word·PPT·Excel 연동), 비용 대비 높은 성능이 필요한 실무 환경에 적합합니다. 오픈소스로 공개돼 있어 자체 서버에 직접 배포도 가능합니다.
3위: Qwen/Qwen3.5-397B-A17B | Image-Text-to-Text
"알리바바의 '눈 뜬' 멀티모달 거인"
알리바바 클라우드의 큐원 팀이 2026년 2월 16일 전격 공개한 최신작입니다. 이름만 봐도 아찔한 규모(3970억 파라미터)지만, 실제 토큰 처리 시 활성화되는 파라미터는 약 170억 개에 불과해 그 능력치에 비해 놀랍도록 효율적으로 동작합니다.
가장 눈에 띄는 특징은 통합된 시각·언어 능력입니다. 이미지, 텍스트, 동영상을 동시에 이해하는 멀티모달 능력을 하나의 모델에서 지원하며, 대화형 AI, 검색 증강 생성(RAG), 시각·언어 이해, 에이전트 워크플로우 등 다양한 분야에 활용하도록 설계됐습니다.
구조적으로도 혁신적입니다. 선형 어텐션(Gated DeltaNet)과 희소 MoE를 결합한 하이브리드 아키텍처를 채택해 높은 처리량과 낮은 지연 시간을 동시에 달성합니다. 201개 언어와 방언을 지원하는 진정한 의미의 글로벌 AI이기도 합니다.
어디에 활용할 수 있을까요? 이미지·동영상 분석이 필요한 비즈니스 인텔리전스, 멀티미디어 콘텐츠 이해, 다국어 에이전트 개발, 복잡한 추론이 필요한 연구 환경 등에 적합합니다. 아파치(Apache) 2.0 라이선스로 상업적 활용도 자유롭습니다.
AI 응용프로그램(Spaces) 톱3
허깅페이스 스페이스는 AI 모델을 웹 브라우저에서 바로 체험할 수 있는 플레이그라운드입니다. 코드 한 줄 없이 최신 AI 기술을 만져볼 수 있죠. 이번 주 가장 뜨거운 스페이스 3곳을 소개합니다.
1위: FireRed Image Edit 1.0 | FireRedTeam
"말 한마디로 사진을 뜯어고치다"
사진 한 장을 올리고 '배경을 눈 덮인 숲에서 지하철역으로 바꿔줘'라고 입력하면? 그대로 됩니다. 파이어레드 이미지 편집(FireRed-Image-Edit)은 정확한 지시 따르기, 높은 이미지 품질, 일관된 시각적 코히어런스(coherence)를 갖춘 오픈소스 편집 모델로, Imgedit·Gedit·RedEdit 등 주요 편집 벤치마크에서 오픈소스 진영 최고 수준을 달성했습니다.
2026년 2월 14일 공개된 따끈따끈한 신작이기도 합니다. 큐원 이미지 텍스트-투-이미지 기반 모델 위에 Pretrain → SFT → RL 전체 파이프라인을 구축해 편집 능력을 부여했으며, 이미지 속 텍스트 스타일을 높은 충실도로 보존하는 것이 특징입니다. 로고나 브랜드 문구가 포함된 제품 이미지 편집에 매우 유용합니다.
어디에 활용할 수 있을까요? 이커머스 상품 이미지 배경 교체, 광고 소재 A/B 테스트용 이미지 변형, 게임 아트 프로토타이핑, 부동산 실내 인테리어 시뮬레이션 등 아파치 2.0으로 상업적 활용도 가능합니다.
2위: SoulX-Singer | Soul-AILab
"가사와 멜로디만 있으면 가수가 필요 없다"
'AI가 노래를 한다'는 말, 이제 진부할 수도 있습니다. 그런데 소울엑스 싱어(SoulX-Singer)는 좀 다릅니다. 무려 4만2000 시간 이상의 보컬 데이터로 학습됐으며, 중국어(보통화), 영어, 광둥어를 지원합니다. 다양한 음악적 조건에서 최신 수준의 합성 품질을 일관되게 달성한다는 평가입니다.
무엇보다 '제로샷(Zero-Shot)' 기능이 핵심입니다. 처음 접하는 가수의 목소리도 최대 30초 샘플만 있으면 그 음색으로 노래를 만들어냅니다. F0 윤곽선(멜로디 조건)이나 MIDI 노트(악보 조건)를 입력해 음정, 리듬, 감정을 정밀하게 제어할 수 있으며, 다른 언어로 커버를 만들어도 목소리의 정체성이 유지됩니다. 가사를 수정해도 원래 발성 방식이 그대로 살아있는 '노래 목소리 편집' 기능도 인상적입니다.
어디에 활용할 수 있을까요? 음반 제작 데모 제작, 광고·영상 BGM 보컬 삽입, 게임 캐릭터 음성 생성, 언어 학습 콘텐츠 제작, K-팝 커버 크리에이터 도구 등에 활용할 수 있습니다. 단, 실제 아티스트 목소리를 무단으로 활용하는 것은 이용 약관상 금지되어 있습니다.
3위: Parakeet STT Progressive Transcription | andito
"브라우저에서 실시간으로, 설치도 없이"
회의록 정리, 강의 녹취, 인터뷰 전사 등은 귀찮고 시간도 오래 걸리죠? 이 스페이스를 쓰면 마이크에 대고 말하는 즉시 텍스트가 실시간으로 화면에 나타납니다. 앱 설치도 필요 없습니다.
이 스페이스는 엔비디아의 패러킷(Parakeet) 모델을 기반으로 합니다. 허깅페이스 오픈 ASR 리더보드 기준 단어 오류율(WER) 6.05%를 기록하며 최상위권에 올라 있는 모델이죠. 특히 브라우저의 웹GPU 기술을 활용해 서버 부담 없이 기기 자체에서 처리하는 방식이라 속도와 프라이버시 모두 잡았다는 평입니다. 누군가의 서버에 내 목소리가 올라가도 걱정 없이 쓸 수 있다는 뜻이기도 합니다.
어디에 활용할 수 있을까요? 기업 회의 자동 녹취, 의료 현장 진료 기록, 법조계 구술 속기, 유튜브·팟캐스트 자막 생성, 장애인 보조 기술 등에 쓸 수 있습니다. CC-BY-4.0 라이선스로 상업적 활용도 가능합니다.
시사점 & 인사이트
이번 주 트렌드를 한마디로 요약하면 '규모와 가성비, 그리고 감각의 확장'입니다.
첫째, 오픈소스 초대형 모델의 본격 경쟁이 시작됐습니다. GLM-5와 큐원 3.5는 규모 경쟁의 끝이 아직 멀었음을 보여줍니다. 수백억~수천억 파라미터급 모델이 오픈소스로 풀리면서, 불과 1~2년 전만 해도 구글·오픈AI만 가능했던 기술을 누구나 자신의 서버에 올릴 수 있는 시대가 됐습니다. 특히 MoE 아키텍처의 확산은 '파라미터는 많되 실제 연산은 적게'라는 이율배반을 현실로 만들고 있습니다.
둘째, AI 가격 파괴의 서막이 열렸습니다. 미니맥스 M2.5의 '시간당 1달러' 전략은 단순한 가격 경쟁이 아닙니다. AI를 서비스형 소프트웨어(SaaS)처럼 시간 단위로 과금하는 새로운 비즈니스 모델의 등장을 알리는 신호탄이기도 합니다. 국내 AI 서비스 기업들도 이 흐름을 예의주시할 필요가 있습니다.
셋째, 멀티모달이 새로운 표준이 되고 있습니다. 큐원 3.5가 텍스트·이미지·동영상을 하나의 모델로 처리하듯, 이제 '텍스트만 다루는 AI'는 경쟁에서 뒤처지는 시대가 됐습니다. 국내 AI 기업들도 멀티모달 역량 강화에 집중해야 할 시점입니다.
넷째, 창작 도구의 민주화가 가속화되고 있습니다. 소울엑스 싱어처럼 음악 생성, 파이어레드 이미지 편집(FireRed Image Edit)처럼 이미지 편집, 패러킷 STT처럼 음성 전사 등 전문가의 영역이었던 모든 것이 대중의 도구로 내려왔습니다. 고가의 장비나 수년간의 훈련 없이도 누구나 자신의 아이디어를 현실로 만들 수 있는 시대입니다. 1인 창작자와 소규모 스타트업의 경쟁력이 획기적으로 높아지는 이유이기도 합니다.
토막 상식: 강화학습(RL)이란… "AI를 칭찬으로 키운다"
이번 주 소개된 GLM-5, 미니맥스 M2.5, 큐원 3.5, 그리고 소울엑스 싱어까지 겉으로 보면 텍스트·이미지·노래로 영역이 제각각이지만, 이들 모두 공통적으로 한 가지 훈련 방식을 씁니다. 바로 강화학습(RL, Reinforcement Learning) 입니다.
개념은 생각보다 단순합니다. 강아지를 훈련시킬 때를 떠올려보세요. "앉아"를 잘 수행하면 간식을 줍니다. 그 경험이 쌓이면 강아지는 "앉아"를 더 잘 하게 됩니다. AI도 똑같습니다. 좋은 답변을 내놓으면 높은 점수(보상)를 주고, 나쁜 답변엔 낮은 점수(패널티)를 줍니다. 수십만 번 이 과정을 반복하면, AI는 점점 더 좋은 답변을 내놓는 방향으로 스스로 진화합니다.
그럼 단순히 정답을 외우게 가르치는 것(지도학습)과 뭐가 다를까요? 지도학습은 "이 상황엔 이 답"이라는 정답지를 보여주는 방식입니다. 강화학습은 정답지 없이, 시행착오를 거치며 AI 스스로 더 나은 전략을 찾아냅니다. 정해진 답이 없는 복잡한 문제, 즉 복잡한 코딩 버그 수정, 여러 단계를 거치는 자율 작업, 자연스러운 노래 생성 같은 과제에서 강화학습이 빛을 발하는 이유입니다.
미니맥스 M2.5는 무려 20만 개 이상의 실제 업무 환경에서 이 방식으로 훈련됐습니다. GLM-5는 비동기식 RL 인프라 '슬라임(slime)'을 자체 개발해 훈련 효율을 획기적으로 끌어올렸고, 소울엑스 싱어는 4만2000 시간의 보컬 데이터 위에서 RL로 노래의 자연스러움을 다듬었습니다.
한마디로, 강화학습은 AI를 '정답 암기 기계'에서 '스스로 생각하는 존재'로 탈바꿈시키는 기술입니다. 그리고 지금 허깅페이스를 달구는 모델들은 모두 그 기술의 수혜자입니다.
마무리
이번 주 허깅페이스는 '더 크게, 더 싸게, 더 넓게'를 동시에 보여줬습니다. AI 모델이 쏟아지는 속도가 점점 빨라지고 있습니다. 이번 주만 해도 중국 3대 AI 세력(Z.ai, MiniMax, Alibaba)이 동시에 초대형 모델을 공개했습니다. 이 경쟁의 수혜자는 결국 우리, 사용자들입니다. 중요한 건 이 기술을 어떻게 활용할 것인가입니다.
※ 외부필자의 원고는 IT조선의 편집방향과 일치하지 않을 수 있습니다.
정원훈 텐에이아이 대표는 한국인공지능진흥협회 이사와 한국디지털자산포럼(KODIA Forum) 정책기획실장을 맡고 있다. 법률AI 서울로봇과 블록ESG 프로젝트를 총괄하며 한국지식재산교육연구학회 이사 겸 기술가치평가위원장과 한국벤처창업학회 이사로도 활동한다. 아시아경제신문사 뉴미디어본부, 매일경제인터넷 금융센터 팀장을 거쳐, SNS 개발과 대안신용평가 시스템, AI 기반 법률 서비스 등 혁신 프로젝트를 주도해 온 IT·금융 전문가다.
Copyright © IT조선. 무단전재 및 재배포 금지.
- 0.9B가 GPT-4o 이긴 비결 [정원훈의 AI 트렌드]
- ‘생각하는 AI·작은 AI·빠른 AI’의 삼파전 [정원훈의 AI 트렌드]
- 목소리 복제 3초, 이미지 이해 AI… ‘감각 융합’ 시대 열렸다 [정원훈의 AI 트렌드]
- 크기의 배신, AI가 작아질수록 똑똑해지는 이유 [정원훈의 AI 트렌드]
- “촬영비 90% 절감” 사진 한 장의 무한 변신[정원훈의 AI 트렌드]
- 사진 한 장이 영상이 되고 3D가 되는 마법, 그 비밀은 [정원훈의 AI 트렌드]
- ‘RED HORSE’ 전략으로 읽는 인공지능 전망 [정원훈의 AI 트렌드]
- 사진 한 장으로 3D 모델 뚝딱… AI, 디자이너 10년 경력 따라잡았다 [정원훈의 AI 트렌드]
- “경차가 슈퍼카 추월”… 거대 AI 꺾은 ‘작은 거인들’ [정원훈의 AI 트렌드]