"엔비디아 GPU보다 2.1배 빨라"…KASIT, 차세대 AI 반도체 기술 개발
김건교 2026. 2. 5. 09:52
보도기사
KAIST 오토GNN(AI 생성이미지)
오토GNN 개발 연구진
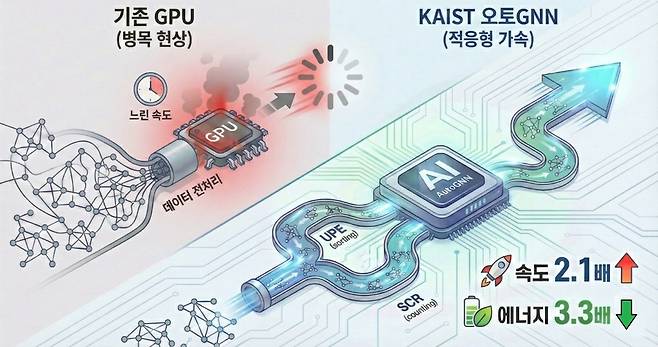
KAIST 전기및전자공학부 정명수 교수 연구팀이 인공지능 서비스의 핵심 기술인 그래프 신경망(GNN) 추론 속도가 엔비디아 GPU보다 2배 이상 빠른 AI 반도체 기술 '오토GNN(AutoGNN)'을 세계 최초로 개발했습니다.
연구팀은 GNN 서비스 지연의 원인이 전체 연산 시간의 70~90%를 차지하는 그래프 전처리 과정에 있다는 점에 주목했습니다.
기존 GPU는 복잡한 연결 관계를 정리하는 이 과정에서 병목이 발생해 속도와 에너지 효율에 한계가 있었습니다.
연구팀은 이를 해결하기 위해 데이터 연결 구조에 따라 반도체 내부 회로 구성을 실시간으로 바꾸는 적응형 AI 가속기 구조를 적용했습니다.
데이터 선별을 담당하는 UPE 모듈과 빠른 집계를 수행하는 SCR 모듈을 반도체 내부에 구현해 데이터 형태가 달라져도 자동으로 최적화된 성능을 유지합니다.
성능 평가 결과, 오토GNN은 엔비디아의 고성능 GPU 대비 처리 속도가 2.1배 빨랐습니다.
일반 CPU에 비하면 성능은 9배 향상됐고, 에너지 소모는 기존 대비 3.3배 절감됐습니다.
이번 기술은 추천 시스템, 금융 사기 탐지, 보안 분석 등 대규모 관계 데이터를 실시간 처리해야 하는 AI 서비스에 즉시 적용 가능할 것으로 기대됩니다.
정명수 교수는 "불규칙한 그래프 데이터를 효율적으로 처리할 수 있는 유연한 하드웨어를 구현한 것이 핵심"이라며 "속도와 전력 효율이 중요한 실시간 AI 서비스 전반에 활용될 수 있을 것"이라고 말했습니다.
이번 연구 성과는 1월 말부터 호주 시드니에서 열리고 있는 컴퓨터 아키텍처 분야 최고 권위 학술대회인 제32회 IEEE HPCA 2026에서 지난 4일 공식 발표됐습니다.
연구팀은 GNN 서비스 지연의 원인이 전체 연산 시간의 70~90%를 차지하는 그래프 전처리 과정에 있다는 점에 주목했습니다.
기존 GPU는 복잡한 연결 관계를 정리하는 이 과정에서 병목이 발생해 속도와 에너지 효율에 한계가 있었습니다.
연구팀은 이를 해결하기 위해 데이터 연결 구조에 따라 반도체 내부 회로 구성을 실시간으로 바꾸는 적응형 AI 가속기 구조를 적용했습니다.
데이터 선별을 담당하는 UPE 모듈과 빠른 집계를 수행하는 SCR 모듈을 반도체 내부에 구현해 데이터 형태가 달라져도 자동으로 최적화된 성능을 유지합니다.
성능 평가 결과, 오토GNN은 엔비디아의 고성능 GPU 대비 처리 속도가 2.1배 빨랐습니다.
일반 CPU에 비하면 성능은 9배 향상됐고, 에너지 소모는 기존 대비 3.3배 절감됐습니다.
이번 기술은 추천 시스템, 금융 사기 탐지, 보안 분석 등 대규모 관계 데이터를 실시간 처리해야 하는 AI 서비스에 즉시 적용 가능할 것으로 기대됩니다.
정명수 교수는 "불규칙한 그래프 데이터를 효율적으로 처리할 수 있는 유연한 하드웨어를 구현한 것이 핵심"이라며 "속도와 전력 효율이 중요한 실시간 AI 서비스 전반에 활용될 수 있을 것"이라고 말했습니다.
이번 연구 성과는 1월 말부터 호주 시드니에서 열리고 있는 컴퓨터 아키텍처 분야 최고 권위 학술대회인 제32회 IEEE HPCA 2026에서 지난 4일 공식 발표됐습니다.

(사진=KAIST)
김건교 취재 기자 | kkkim@tjb.co.kr
Copyright © TJB