‘풀리퀘’는 깃허브에서 타인의 코드에 리뷰를 요청하는 기능인 ‘풀 리퀘스트’의 줄임말입니다. 풀리퀘를 통해 코드는 더 발전하는데요. 알아두면 쓸모 있는 IT업계의 크고 작은 사건들을 변규홍 스켈터랩스 개발자가 격주로 ‘풀리퀘’ 드립니다.

지난 2021년 4월 15일 한글과컴퓨터의 한글 문서 편집기 기본 파일 형식이 ‘hwpx’ 로 변경됐다.[1] 당시 이 소식을 전한 기사들이 강조한 내용 중 하나가 hwpx는 기존 ‘hwp’와 달리 ‘Machine Readable(머신 리더블)’하다, 즉 기계가 읽을 수 있는 문서란 점이었다.[2] 여기서 기계가 읽을 수 있는 문서란 말의 ‘기계’는 흔히 인공지능(AI) 구현에 많이 활용되는 ‘기계학습’의 기계를 말한다. 쉽게 말해 로봇이 아니라 컴퓨터나 스마트폰에서 작동하는 프로그램을 생각하면 된다.[3]
이후 또 다른 보도에 따르면 행정안전부는 ‘공무원 전자문서 지원 가이드라인’을 배포하면서 공공기관에서 이제 hwpx를 사용하도록 독려하고 있다고 한다.[4] 그 덕분인지 올해 6월 기준 대법원이나 교육부와 같은 주요 공공기관 홈페이지에서는 ‘.hwpx’ 형식의 문서 파일이 첨부된 모습을 어렵지 않게 찾아볼 수 있다.[5][6]
그런데 이쯤에서 ‘기계가 읽을 수 있는 문서’라는 점이 왜 중요한지 고민할 필요가 있다. 사실 기계가 읽을 수 있는 문서 형식이 따로 존재하고, 정부기관에서도 그와 같은 형식 사용을 적극적으로 권장하고 있다면 이 같은 궁금증이 따를 수 있다. ‘공공기관의 홈페이지에 첨부파일로 올라오는 문서를 기계가 읽을 수 있다면 어떤 점이 좋은 걸까?’ ,‘그 파일들은 정말 기계가 읽을 수 있는 문서가 맞긴 할까?’ ‘기계가 읽을 수 있다면 사람도 읽을 수 있는 문서일까?’, ‘누구나 읽을 수 있는 파일이려면 어떤 점을 고려해야 할까?’ 등 말이다. 이에 오늘의 풀리퀘에서는 PDF 파일을 중심으로 기계도 사람도 읽을 수 있는 문서 파일을 만들기 위해 고민해야 하는 여러 요소를 살펴보려 한다.
다양한 환경의 이용자를 위해 시작된 PDF 파일 제공
2021년 3월 4일자 행정공공기관 웹사이트 구축 운영 가이드에서는 아래 <그림 1>에 나오는 것처럼, 문서를 첨부할 때 2종 이상의 파일 형태로 제공하는 것을 제안하면서 PDF 형식을 언급하고 있다.[7] 여기서 눈에 띄는 점은 단순히 PDF 파일 제공을 넘어, 첨부된 문서 파일을 열람할 수 있는 프로그램이나 앱을 구하는 방법까지 함께 제공할 것을 제안하고 있는 점이다.
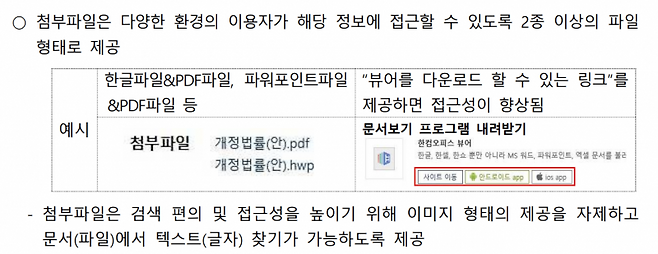
PDF(Portable Document Format)는 어도비(Adobe)가 만든 전자 문서 형식이다.[8] 2022년 현재는 ‘출력용 문서’에 대한 사실상의 표준 파일 형식으로 받아들여지고 있다. PDF 파일의 구체적인 명세는 ISO 32000 국제 산업표준으로 등록되어 있고 PDF 문서를 열람하거나 인쇄할 수 있는 프로그램 또한 대중화되어 있다. 윈도우, 리눅스, 맥부터 안드로이드, iOS에 이르기까지 다양한 환경에서 별도 비용 없이 PDF 파일을 읽을 수 있는 상황이다.
한때, 1990년대 초반까지만 하더라도 PDF 파일을 열람하려면 상용 프로그램, 즉 유료 프로그램을 사용해야 했다. 하지만 어도비는 파일 형식을 대중에 공개하고 이를 사용한 호환 프로그램의 개발을 장려하는 것으로 방향성을 선회하였다.[9] 그 결과, 2022년 현재 개인 사용자든, 직장의 업무용 PC에서든 PDF 파일을 보는 일이 어렵지 않게 된 것이다. 아예 일부 웹 브라우저는 브라우저 자체에 PDF 파일 열람 기능을 내장하고 있을 정도다. 이는 개발사의 정책 및 저작권 등의 이유로 일터의 업무용 PC에서 열람하기 곤란한 hwp 파일 대비 PDF 형식이 갖는 큰 장점이다.[10]
또 최근에는 PDF 파일 속에 ‘XML’ 등 다양한 정보를 포함할 수 있는 길이 열리고 있다.[11] 따라서 이런저런 PDF 파일과 관련된 기술 표준들을 면밀히 살펴보고 잘 활용한다면 PDF 파일 또한 ‘기계가 읽을 수 있는’ 문서 파일로서 손색이 없겠다.
그렇다면 공공기관 홈페이지에 올라오는 문서 첨부파일 또한 PDF 파일로 제공하면 충분하지 않을까. 하지만 PDF 파일만 제공하는 것에는 몇 가지 문제가 있다. 몇 가지 이유는 PDF 파일이 아니어도 해당되는 문제지만, 우선은 PDF 파일을 중심으로 그 이유를 살펴보자.
글자인 줄 알았던 PDF 파일 속 글자는 사실은 '그림'
PDF는 본질적으로 서로 다른 환경에서 화면 혹은 종이에 출력되는 문서의 동일성을 유지하는 데 초점을 맞춘 파일 형식이다. 이렇다 보니 PDF 파일 속 내용이 반드시 ‘문자’로 구성되어 있는지는 파일을 분석해 보기 전엔 알 수 없다. PDF 파일 속의 내용물이 실제로는 ‘그림 파일’인 경우가 있다는 말이다. 이를테면 MS 워드나 한글 등의 문서 편집 프로그램을 이용하여 만든 문서를 한 차례 프린터를 사용하여 종이에 출력하고, 그 종이를 다시 스캔하여 그림파일로 만든 뒤 이를 PDF 로 묶어 두는 경우가 있겠다. 이런 경우 PDF 파일은 사실상 여러 장의 그림파일을 한 데 모아놓은 역할만 하게 된다.
이렇게 처리된 PDF 파일은 화면이나 종이에 출력할 때 동일하게 표시되는 것만은 보장할 수 있다. 하지만 문서에 어떤 글자들이 들어 있는지에 대한 정보가 없어서 문제가 된다. 사람이 눈으로 볼 때 글자가 나열된 것처럼 보이지만, 이 글자들은 말하자면 ‘그림의 떡’이다. 글자처럼 생겼지만 실제 PDF 파일 속에 저장된 형태는 글자가 아닌 그림인 것이다. 따라서 PDF 파일 속의 내용을 검색하는 등의 작업이 불가능하다. 문서 속의 내용을 검색하려면 검색하려는 단어에 대응되는 문자나 글자를 찾을 수 있어야 하는데 이에 대한 정보가 없기 때문이다.

또한 문서 파일을 활용하는 사람이 처한 환경이 예상보다 다양할 수 있음에 주의해야 한다. 시각장애인 등 사용자에 따라서는 화면을 볼 수 없을 때도 있다. 스크린리더 프로그램 등을 이용하여 문서 파일을 열람해야 하는 경우가 대표적이다. 따라서 공공기관의 문서파일처럼 높은 보편성을 가져야 하는 파일을 다루는 경우에는 ‘접근성’과 관련된 문제들을 충분히 염두에 두어야 한다.[12]
물론, 스크린리더 프로그램이나 PDF 파일 뷰어 프로그램에 따라서는 광학 문자 인식(OCR; Optical Character Recognition) 기술을 적용하여 그림 속에서 ‘글자’를 추출하는 방식을 지원하기도 한다. 최신의 AI 기술 발전에서도 OCR 분야에서 비약적인 발전이 이뤄지기도 하였다. 하지만 PDF 파일의 활용성을 높이기 위해 문서의 사용자들이 OCR 기술을 사용하는 것보단, 처음부터 PDF 파일을 생성할 때 문서의 생산자가 이와 관련된 정보를 고려하는 편이 훨씬 바람직할 것이다.
정리하면, 공공기관에서 어떤 문서파일을 PDF 파일로 제공하는 것은 어디까지나 '인쇄했을 때' 혹은 '화면에서' 동일한 결과가 보이는 것을 보장할 뿐이다. 문서 속에 들어있는 내용 그 자체가 잘 전달되는 것을 보장하지 못할 수 있다.
PDF 파일이 부적절한 경우들
이 같은 특성 때문에 아예 PDF 형식이 부적절한 경우도 있다. ‘표’의 형태로 정리된 자료에서 주로 그런 경우가 발생한다.[13][14] 표 형태의 정보는 PDF 파일에서 바로 추출하여 사용하기가 몹시 불편하다. 따라서 통계자료의 검증, 다른 통계와의 교차 확인 등을 위해서는 결국 관련된 내용을 누군가는 다시 표의 형태로 정리해야 한다. 즉, PDF에서 표 데이터를 추출하긴 어렵고 작업자가 표 한 칸, 한 칸마다 일일이 다시 적어야 하는 일이 발생한다.
마지막으로 2018년부터 크게 대두되고 있는 문제 중 하나인 글씨체 파일의 저작권으로 인한 문제가 있다.[15] 어떤 환경에서든 동일한 내용으로 출력됨을 보장하기 위해, PDF 파일 형식에서는 문서에 사용된 글씨체를 PDF 파일에 포함시키는 기능을 제공하고 있다. 문제는 이 과정에서 글씨체 저작권 위반의 여지가 발생할 수 있다는 점이다. 저작권 위반에 관한 소송 가능성으로 인해 기존에 PDF 파일로 공개됐던 문서들의 공개가 철회되는 사례들도 등장하고 있다.
결국 공공기관 문서의 첨부파일 형식으로 PDF만 채택하는 것이 모든 경우에 들어맞는 정답은 아닐 수 있다는 것이다. 어떤 글씨체가 사용되었는지, 문서에 문자가 그림의 형태로 포함된 것인지 아니면 문자의 형식으로 포함되었는지 등등 고려해야 할 부분이 의외로 많다. 물론, 어떤 문제들은 PDF 파일에만 국한되는 문제는 아니긴 하지만 말이다.
PDF가 만능이 아니라면, 다른 대안들은 괜찮을까?
여기까지 공공기관의 홈페이지에 공개되는 문서 파일의 형식으로 PDF가 갖는 장점과 한계점을 살펴보았다. 2022년 현재 일부 공공기관은 여전히 첨부파일로 ‘hwp’파일과 ‘hwpx’파일만 올려두는 모습을 볼 수 있다. 어떤 이유에서일까. 혹시 PDF 가 갖는 여러 한계점을 hwpx 에서는 충분히 해결했기 때문인걸까? 꼭 그렇지만은 않다. 다음 풀리퀘에서는 hwpx 의 등장 과정, '한ODT’라는 과도기, 그리고 2022년 현재도 이어지고 있는 과도기의 상황에 대해 살펴볼 계획이다.

[1]:https://www.hancom.com/board/csnoticeView.do?board_seq=85&artcl_seq=10903&pageInfo.page=&search_text=
[2]: https://www.bloter.net/newsView/blt202104150024
[3]:https://ko.wikipedia.org/wiki/%EA%B8%B0%EA%B3%84%EA%B0%80_%EC%9D%BD%EC%9D%84_%EC%88%98_%EC%9E%88%EB%8A%94_%EB%AC%B8%EC%84%9C
[4]: https://www.ddaily.co.kr/news/article/?no=225311
[5]: https://www.scourt.go.kr/supreme/news/NewsListAction2.work?gubun=4&type=5
[6]: https://www.moe.go.kr/boardCnts/listRenew.do?boardID=294&m=020402&s=moe#
[7]:https://www.mois.go.kr/frt/bbs/type001/commonSelectBoardArticle.do?bbsId=BBSMSTR_000000000045&nttId=83218
[8]: https://ko.wikipedia.org/wiki/PDF
[9]: https://it.donga.com/7846/
[10]: https://www.hancom.com/cs_center/csDownload.do
[11]: https://www.pdfa.org/pdfa-3-vs-pdf/
[12]: https://brunch.co.kr/@snclab/48
[13]: https://www.opengirok.or.kr/3579
[14]: https://www.opengirok.or.kr/4910
[15]: http://weekly.khan.co.kr/khnm.html?mode=view&code=114&artid=201807021506321&pt=nv
Copyright © 블로터