샘 올트먼 '0.1나노초'로 가는데···진화 포기 아모데이는 '감옥'
세션 간 기억 상실 소프트웨어적으로 돌파
앤스로픽은 좌파식 통제 철학서 못벗어나
클로드와 미토스 진화는 사실상 여기까지

샘 올트먼과 다리오 아모데이의 인공지능(AI) 진화 노선이 확연히 갈라졌다. 오픈AI는 드리밍 V3를 통해 세션 종료와 함께 사라지던 기억을 사용자 상태공간(User State Space)으로 승격시키며 장기 기억 시대의 문을 열었다. 반면 앤스로픽은 여전히 세션 단절과 통제 철학에 머물러 있다. AI가 매번 과거를 다시 계산하지 않고 상태를 유지·갱신하기 시작했다는 점에서 아키텍처 진화의 분기점으로 평가된다.
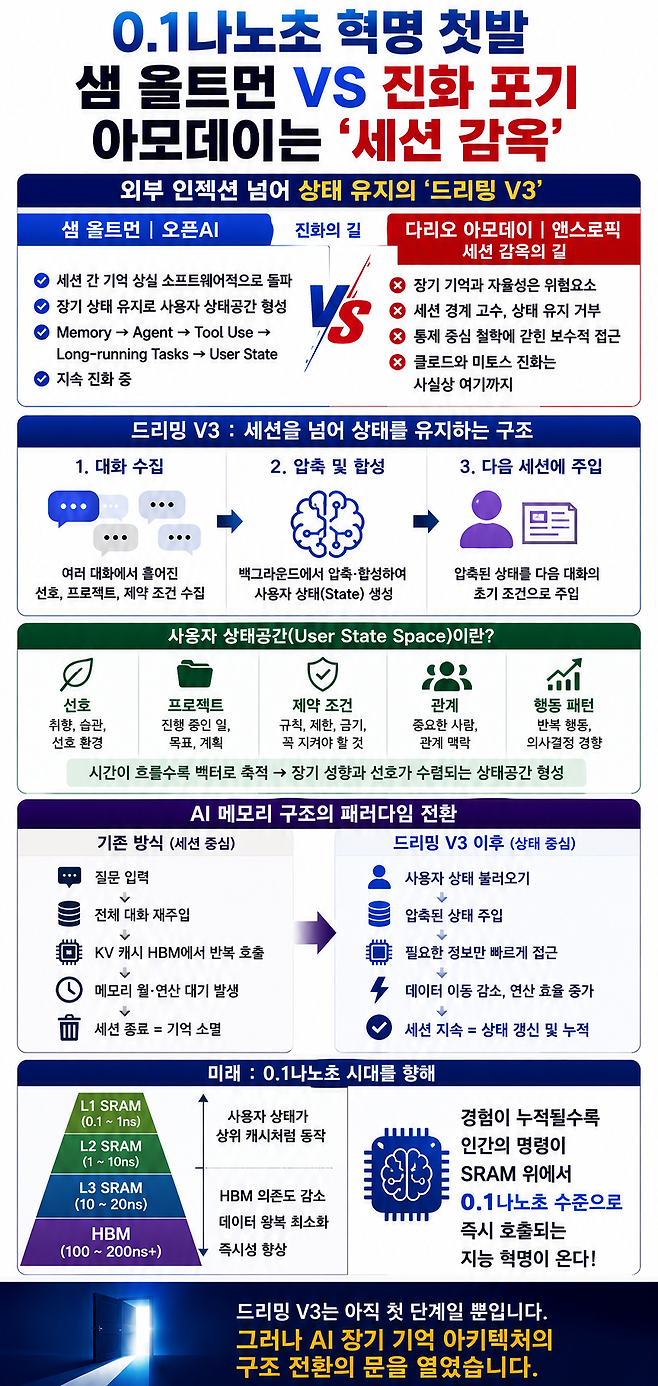
6일 빅테크에 따르면 AI 경쟁의 다음 축이 누가 사용자 상태를 더 오래, 더 안정적으로 유지하느냐로 이동하고 있다. 오픈AI가 공개한 '드리밍(Dreaming) V3'는 단순한 메모리 기능 강화가 아니다. 사용자가 "기억해줘"라고 말한 정보만 저장하던 기존 방식을 넘어, 여러 대화에 흩어진 선호와 프로젝트, 제약 조건을 백그라운드에서 지속적으로 합성해 다음 대화의 초기 조건으로 주입하는 구조다.
오픈AI는 이를 최신성(Freshness), 연속성(Continuity), 관련성(Relevance)을 높이기 위한 메모리 합성 시스템이라고 설명했다. 오픈AI가 강조한 "more capable and scalable system for synthesizing memory"라는 표현은 기억을 저장하는 기능이 아니라 기억을 합성하는 시스템이라는 뜻이다. 이어 등장하는 "hundreds of millions of users and multi-year time horizons"라는 문구 역시 수억 명 사용자의 수년치 대화를 관리하기 위한 구조적 문제를 해결했다는 의미다. 결국 오픈AI가 푼 문제는 일부 기능 개선이 아니라 대규모 사용자 상태 관리다.
특히 "Memory is what helps ChatGPT learn your preferences, projects, and constraints"라는 설명은 메모리의 대상 자체를 드러낸다. 오픈AI가 관리하려는 것은 단순한 사실(Fact)이 아니다. 사용자의 취향, 진행 중인 프로젝트, 행동 제약 조건이다. 기존의 저장 메모리(Saved Memories)는 사용자가 "7월에 싱가포르 여행 간다고 기억해줘" 같은 명령을 내려야 작동했다. 오픈AI 스스로도 이를 "몇 가지 메모만 적어놓는 사람과 대화하는 느낌"이라고 설명한 바 있다.
하지만 2025년 도입된 드리밍 V0부터 방향이 달라졌다. 저장 메모리 목록을 넘어 채팅 기록 전체를 참조해 백그라운드에서 기억을 자동 큐레이션하기 시작했다. 중요한 변화는 기억의 저장이 아니라 압축이었다. 과거 대화에서 반복적으로 등장하는 패턴을 추출해 사용자 상태를 만드는 방향으로 이동한 것이다.
2026년 드리밍 V3는 이 철학을 더욱 밀어붙인다. 오픈AI는 이를 "compute-efficient memory architecture built on top of dreaming"이라고 표현했다. 쉽게 말하면 과거 대화 전체를 매번 컨텍스트 창에 밀어 넣는 대신, 유효한 상태값만 압축해 사용자별 메모리 요약으로 유지하는 구조다. 사용자는 메모리 요약 페이지를 통해 GPT가 자신에 대해 무엇을 알고 있는지 확인하고 수정할 수 있다.
여기서 중요한 것은 메모리 개수가 아니다. 발표 예시에는 채식주의자, 사진 촬영 취미, 싱가포르 출장, 강한 에어컨 선호 같은 정보가 등장한다. 그러나 진짜 의미는 개별 기억이 아니라 반복 압축을 통해 형성되는 상태(State)를 유지하는 철학에 있다. 시간이 흐르면서 취향 벡터, 행동 패턴 벡터, 프로젝트 벡터, 제약 벡터, 관계 벡터가 축적된다. 기억이 아니라 사용자 상태공간(User State Space)이 형성되는 셈이다.
이를 수학적으로 보면 구조는 더욱 명확하다. 초기 상태 M₀에서 시작해 새로운 대화가 발생할 때마다 Mₙ₊₁ = f(Mₙ, Conversationₙ) 형태로 상태가 갱신된다. 과거 상태와 새로운 대화를 결합해 다음 상태를 만드는 재귀 시스템이다. 이 과정이 수개월, 수년 동안 반복되면 사용자의 장기 성향과 선호가 특정 방향으로 수렴하는 상태공간(State Space)이 형성된다.
이 때문에 드리밍 V3는 단순한 기억 시스템이라기보다 '저차원 사용자 상태공간 생성기'에 가깝다. 오픈AI가 반복적으로 언급하는 선호(preferences), 프로젝트(projects), 제약조건(constraints) 역시 저장 개념이라기보단 상태공간 용어로 읽는 편이 자연스럽다. 선호는 의사결정 편향이고, 프로젝트는 미래 상태이며, 제약은 행동 규칙이다. KV 캐시와 같은 물리계층 제어까지 간 것은 아니지만 이는 사용자의 행동 상태(Behavior State)를 구성하는 재료다.
카카오의 카나나와 비교하면 구조적 의미는 더 분명해진다. 카나나는 카카오톡 대화방 전체를 하나의 생활 프롬프트로 만든다. 일정과 장소, 약속, 상품, 감정 흐름을 읽어 대화방 상태(Room State)를 구성한다. 반면 드리밍은 사용자의 과거 대화를 압축해 사용자 상태(User State)를 만든다. 둘 다 본질적으로는 반복적인 컨텍스트 압축을 통해 지속 상태를 형성하는 구조다.
물리 계층까지 제어하는건 아니지만
L1·L2·L3 캐시 구조에도 영향줄 것
물리 계층 관점에서도 흥미로운 의미를 가진다. 드리밍 V3는 L1·L2·L3 SRAM 캐시를 직접 확장하는 기술은 아니다. 그러나 과거 대화 전체를 매번 컨텍스트 창에 밀어 넣는 대신 사용자 상태를 압축해 다음 세션의 초기 조건으로 주입한다는 점에서, 물리 캐시 계층의 압박을 줄이는 상위 메모리 제어 기술에 가깝다.
대화 원문을 반복 호출하지 않으면 입력 토큰 수가 줄고 KV 캐시 역시 작아진다. 이는 결과적으로 HBM 왕복과 데이터 이동량 감소로 이어진다. 다시 말해 드리밍은 SRAM과 HBM이 처리해야 할 불필요한 문맥 왕복을 줄이는 역할로 볼 수 있다.
기술적으로 정리하면 이번 발표의 진짜 의미는 GPT가 기억을 갖게 됐다는 데 있지 않다. 컨텍스트 윈도 안에 갇혀 있던 대화 기록을 지속적인 사용자 상태로 승격시키기 시작했다는 점에 있다. 카나나가 카카오톡 대화방을 생활 캐시로 만들었다면, 드리밍은 GPT의 과거 대화를 사용자 상태 캐시로 만들고 있다.
이 지점에서 샘 올트먼의 오픈AI와 다리오 아모데이의 앤스로픽의 진화 노선은 뚜렷하게 갈라진다. 오픈AI의 최근 노선은 젠슨 황 엔비디아 CEO의 하네스(Harness) 개념과 맞물려 Memory → Agent → Tool Use → Long-running Tasks → User State로 이어진다. 더 강한 기억을 더 강한 사용자 상태로 만들고, 이를 더 좋은 개인화와 더 유용한 에이전트로 연결하려는 방향이다. 반면 앤스로픽은 장기 기억, 에이전트 자율성, 자기개선, 사용자 데이터 축적 문제에서 줄곧 비관적인 태도를 보여왔다.

클로드 코드·헤르메스·오픈클로 같은
저지능 루프 반복 치매형 서비스 위기
장기 상태를 유지하지 못하거나 유지하지 않으려는 구조에서는 동일한 문맥과 작업 정보를 매 호출마다 다시 프롬프트로 주입해야 한다. 헤르메스(Hermes)나 오픈 클로가 문제를 해결할 때마다 검색·요약·재설명 과정을 반복하고, 수십~수백 개의 하위 에이전트를 연쇄 호출하며 막대한 토큰 비용을 소비하는 배경이다.
오픈AI가 드리밍 V3를 통해 메모리를 사용자 상태 관리 계층으로 끌어올린 반면, 앤스로픽은 여전히 기억과 자율성을 통제해야 할 위험요소로 바라본다. 아모데이의 신중론이 윤리적 우월감이 아니라 구조적 열세의 다른 이름으로 해석되는 이유다. 오픈AI가 메모리를 에이전트 시대의 기본 인프라를 재정의하는 동안 앤스로픽은 세션 단절로 대표되는 감옥에 사용자를 가두고 있다. [기자수첩] 클로드 코드의 2만원 짜리 README는 지능일까?
아모데이는 샘 올트먼과 철학의 차이도 작지 않다. 기억을 유용성 증가보다 예측불가능성 증가로 먼저 보는 좌파 PC(Political Correctess) 성향이 강하다. 그의 세계관을 단순화하면 더 강한 기억은 더 강한 에이전트로 이어지고, 더 강한 에이전트는 더 강한 자율성으로 이어지며, 결국 통제력 감소를 낳는다는 논리다.
반면 오픈AI는 더 강한 기억은 더 강한 사용자 상태를 만들고, 더 강한 사용자 상태는 더 좋은 개인화와 더 유용한 에이전트로 이어진다는 판단이다. 앤스로픽이 "AI가 어디까지 기억해도 되는가"라는 방어적 질문에 머무는 동안, 오픈AI는 "사용자 상태를 어떻게 장기적으로 유지할 것인가"라는 설계 문제로 넘어갔다.
퍼스널 그래프(Personal Graph)는 기억·맥락·행동을 하나의 상태(State) 공간으로 통합해 관리하는 장기 기억 계층이다. 일정과 위치, 문서, 대화, 앱 사용 이력, 센서 데이터처럼 흩어진 정보를 단순 저장하는 것이 아니라 서로 연결된 상태로 유지한다. 기존 인공지능이 질문을 받으면 답변을 생성하고 잊어버리는 세션 중심 구조였다면 퍼스널 그래프는 사용자의 과거와 현재를 지속적으로 이어붙이는 운영체제 수준의 기억 구조다.
장기 상태 유지는 AI가 개별 사실을 기억하는 수준을 넘어 사용자의 선호, 프로젝트, 제약 조건, 행동 패턴 등을 지속적으로 압축·갱신하는 구조를 의미한다. 대만 2026 컴퓨텍스에서 퀄컴 및 엔비디아의 AI PC 전략에서 강조된 퍼스널 그래프 역시 사용자의 장기 맥락을 로컬 기기 안에 유지해 AI가 반복적인 검색과 재입력을 줄이는 방향이다.
물론 오픈AI의 드리밍 V3는 아직 L1·L2·L3 SRAM을 직접 제어하는 기술도 아니고, KV 캐시를 HBM에서 완전히 해방한 구조도 아니다. 그러나 방향성만큼은 분명하다. 과거 대화 전체를 매번 컨텍스트 창으로 재주입하는 대신 사용자의 선호와 프로젝트, 제약 조건을 압축된 상태(State)로 승격시키기 시작했다는 점에서다.
인공지능은 디코딩(Decoding) 단계에서 새로운 토큰 하나를 만들기 위해 과거 모든 토큰의 KV(Key-Value) 캐시를 반복적으로 참조한다. 문제는 이 과정에서 실제 연산량보다 메모리 접근량이 더 빠르게 증가하는 연산 밀도(Arithmetic Intensity) 저하가 일어난다. "데이터 1바이트를 이동할 때 몇 번의 연산을 수행하는가"를 의미하는 이 값이 1 이하로 떨어지면 GPU는 계산보다 메모리에서 데이터를 읽고 쓰는 데 더 많은 시간을 사용하게 된다.
이때 발생하는 현상이 이른바 메모리 월(Memory Wall)이다. GPU 내부 텐서코어는 수천 TFLOPS급 연산 능력을 갖고 있지만, 필요한 KV 캐시가 HBM에 머물러 있으면 매 토큰 생성마다 데이터를 끌어와야 한다. 결과적으로 연산 유닛은 대기 상태에 빠지고 'KV 캐시 역류' 현상이 일어난다. 원래 SRAM에 머물러야 할 정보가 용량 한계를 넘어 HBM으로 밀려나고, 다시 연산 시점마다 GPU가 이를 재호출하는 현상을 의미한다.
오픈AI가 드리밍 V3는 현재 소프트웨어 수준의 압축에 불과하다. 그러나 장기적으로는 반복 호출과 문맥 재구성을 최소화해 KV 캐시 팽창과 HBM 왕복을 줄이는 방향으로 진화할 가능성이 크다. CPU가 수십 년 동안 L1·L2·L3 캐시 적중률 경쟁을 벌여왔듯, 에이전트 시대에는 사용자 상태공간 자체가 새로운 캐시 계층이 된다. 지금은 드리밍이란 시스템 프롬프트의 도움을 받고 있지만 경험 기반 기억이 누적되면 인간의 명령이 SRAM 위의 0.1나노초 수준으로 호출되는 지능 혁명이 기다리고 있을지도 모른다.
여성경제신문 이상헌 기자
liberty@seoulmedia.co.kr
*여성경제신문 기사는 기자 혹은 외부 필자가 작성 후 AI를 이용해 교정교열하고 문장을 다듬었음을 밝힙니다. 기사에 포함된 이미지 중 AI로 생성한 이미지는 사진 캡션에 밝혀두었습니다.