NIA, 유해 표현 검출하는 AI 모델 및 학습용 데이터 공개
이한규 기자 2025. 4. 14. 16:04
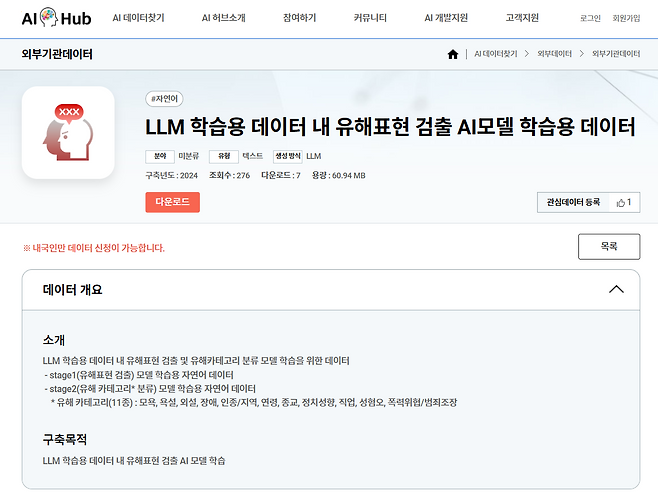
한국지능정보사회진흥원(NIA)과 한국정보통신기술협회(TTA)는 인공지능(AI) 허브를 통해 대규모 언어 모델(LLM) 학습용 데이터 내의 ‘유해 표현 검출 인공지능 모델’과 ‘유해 표현 학습용 데이터’를 공개했다고 14일 밝혔다.
AI 허브는 과학기술정보통신부와 NIA가 운영하는 국내 최대 AI 학습용 데이터 제공 플랫폼이다.
이번 유해 표현 검출 AI 모델 및 데이터는 과학기술정보통신부 초거대 AI 확산 생태계 조성 사업의 일환으로 개발됐다. LLM 데이터의 품질검증 과정에서 유해성을 측정하기 위한 것으로, 자체 성능 검증 결과 80~90% 정확도를 달성했다.
공개된 인공지능 모델은 말뭉치 데이터에서 유해 표현을 검출하고 다양한 카테고리로 분류한다. 학습에 활용한 데이터는 유해 표현 검출용 데이터 20만 건과 유해 표현 카테고리 구분용 데이터 21만 건으로 구성됐다.
AI 모델과 데이터는 AI 허브를 통해 누구나 활용할 수 있다. NIA 측은 인공지능이 생성하는 콘텐츠의 안전성을 강화하고 다양한 산업 분야에서 인공지능 윤리를 지키는 데 일조할 수 있을 것으로 기대한다.
황종성 NIA 원장은 “인공지능 기술의 발전은 기술적 진보뿐만 아니라 사회적 책임을 담보할 수 있는 윤리적 고려가 반드시 병행돼야 한다”며 “이번 AI 모델 및 데이터의 공개가 한국어 LLM의 신뢰성과 안전성을 강화하는 계기가 될 것으로 기대한다”고 말했다.
이한규 기자 hanq@donga.com
Copyright © 동아일보. All rights reserved. 무단 전재, 재배포 및 AI학습 이용 금지
동아일보에서 직접 확인하세요. 해당 언론사로 이동합니다.
- 김두관, 민주당 경선 거부 선언…“특정 후보 추대하는 경선룰”
- 尹 “내란몰이에 겁먹은 사람들이 수사기관 유도 따라 진술”
- 민주, 공수처에 韓대행 고발 “헌법재판관 지명 직권남용”
- 압도적 지지 없는 국힘 주자들…의원들 ‘줄설 곳’ 고민중
- [단독]연세 의대, 1~3학년에도 이번주 유급 예정 통보
- ‘포천 오폭’ 조종사 이어 부대 지휘관 2명 입건
- 韓대행 “트럼프 통화 후 관세 유예…우리 협상 의지에 동의한것”
- 이재명 “AI 투자 100조원 시대 열겠다…국민 모두 무료로 활용”
- 권영세 “주 40시간 유지하되 금요일 조기퇴근 ‘주 4.5일제’ 공약 추진”
- 부산 사상구에 또 싱크홀…이번에도 도시철도 공사 현장