붙이고 압축하고...HBM에 맞서는 메모리 전쟁[김창영의 실리콘밸리Look]
그록은 칩 80% 메모리로 채우는 방식
구글은 데이터 압축해 공간 확보 고안
HBM도 온칩 메모리 구현될 가능성도

고대역폭메모리(HBM)가 반도체 시장을 휩쓸고 있는 이유는 더 이상 ‘무어의 법칙’이 통하지 않기 때문이다. 무어의 법칙은 트랜지스터 크기를 줄여 동일한 칩 안에 들어가는 트랜지스터 양을 2배 늘리고 컴퓨팅 성능도 2배 향상시킨다는 이론이다. 트랜지스터를 10나노미터(㎚·1㎚=10억분의 1m) 이하로 줄여가며 2년 주기의 무어의 법칙을 가까스로 지켜왔지만 이제는 기술적 한계에 봉착했다. 메모리 대역폭(메모리 데이터를 읽고 처리하는 속도)을 높여 성능을 끌어올리는 방식이 대안으로 각광받으면서 HBM 열풍이 불었다. 2013년 SK하이닉스(000660)가 세계 최초로 HBM 개발에 성공한 뒤 삼성전자(005930)와 SK하이닉스가 기술 경쟁에 매달린 끝에 HBM이 초호황기를 맞았다.
하지만 HBM도 안주하고 있을 수 없는 상황이다. 인공지능(AI) 반도체 시장이 HBM에 주도권을 뺏기지 않기 위한 견제에 나섰기 때문이다. AI 반도체 리더 엔비디아가 대표적이다. 2주 전 엔비디아 연례 기술 컨퍼런스인 ‘GTC 2026’에서 가장 주목을 끈 것은 추론 특화 맞춤형 인공지능(AI) 칩인 ‘그록3 LPU’였다. 그록3 LPU는 메모리 시장에서 주목도가 낮았던 S램(정적램)을 써 추론 속도를 높여 눈길을 끌었다. D램(동적램)을 여러개 쌓아서 대역폭을 높인 HBM 탑재 칩과 대척점에 있다. 이를 두고 엔비디아가 HBM 대항마로 S램을 내세웠다는 해석이 나왔다.
트랜지스터 집적만으로 그래픽처리장치(GPU)·중앙처리장치(CPU)와 같은 AI 칩을 발전시키는 것이 어려워진 만큼 앞으로 메모리 기술 경쟁이 불가피하다. 특히 삼성전자·SK하이닉스가 주도하는 HBM과 HBM에 대항하는 새로운 기술들이 도전장을 낼 전망이다. 두뇌 역할을 하는 프로세서와 데이터를 저장하는 메모리 사이 거리를 더 줄이거나 메모리 적층 단수를 높이는 방식과 같은 기술 경쟁이 치열해질 전망이다.
올해 초 오픈AI와 100억 달러(15조 1780억 원) 규모 투자 계약을 맺은 세레브라스 시스템즈는 추론용 AI 칩을 개발하는 실리콘밸리 유망 스타트업 가운데 대표주자로 꼽힌다. 세레브라스의 가장 큰 특징은 웨이퍼를 자르지 않고 웨이퍼 판 위에 프로세서와 메모리를 모두 올리는 ‘웨이퍼스케일엔진(Wafer Scale Engine·WSE)’ 기술을 쓴다는 점이다. 웨이퍼를 잘라 프로세서 칩을 만들고 그 주변에 메모리 등을 연결하는 것이 일반적이지만 세레브라스는 온칩 메모리(On chip memory) 방식으로 통신 속도를 높이고 병목 현상을 낮추는 기술을 개발했다.
세레브라스도 엔비디아가 우회 인수한 그록처럼 S램을 쓴다. S램은 저장 용량은 작지만 전원이 공급되는 한 저장된 내용을 계속 기억하기 때문에 주기적으로 갱신할 필요가 없어 지연이 적다. 세레브라스는 2024년 11월 자사 제품 속도가 GPU의 75배를 기록했다고 밝혔을 만큼 S램이 HBM보다 싸고 빠르지만 S램의 한계점은 용량이 작다는 것이다. 그록3 LPU에 들어간 S램 용량은 500MB(메가바이트)로 엔비디아 루빈 GPU에 탑재된 288GB HBM과 비교하면 500분의 1에 불과하다.
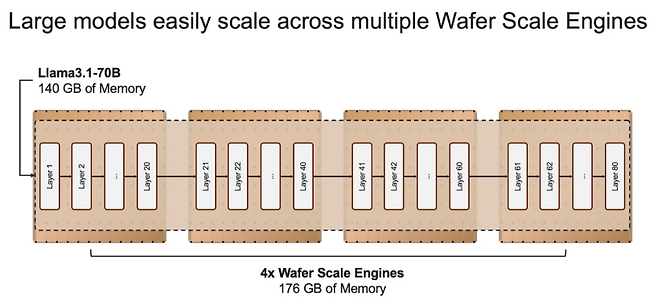
세레브라스가 2년 전 공개한 자료에 따르면 세레브라스 칩 자체가 크기 때문에 그록보다 용량이 높은 44GB S램을 쓰지만 여전히 HBM에는 크게 못 미친다. 세레브라스는 ‘어떻게 메모리 대역폭 장벽을 허무는가’라는 질문에 단일 칩에 44GB S램을 통합해 엔비디아 H100 GPU 대비 7000배 높은 메모리 대역폭을 제공한다고 답했다. 그러면서 AI 모델이 단일 웨이퍼 메모리 용량을 초과할 경우에는 자사 칩 ‘CS-3’ 여러 개를 연결해 병목을 없앤다고 밝혔다. 칩 4개를 연결하면 메모리 용량이 176GB가 되는 식이다. 그록이 칩 70~80%를 저용량 S램으로 가득 채우는 반면 세레브라스는 용량이 큰 S램을 탑재하되 이마저도 부족하면 웨이퍼 칩을 연결해 문제를 해결하겠다는 것이다. 세레브라스는 자사 기술이 그록 대비 6배 빠르고, 비싼 엔비디아 GPU와 HBM을 쓰지 않고도 추론 개발에 최적화할 수 있다는 입장이다.
구글은 데이터를 압축시켜 메모리 사용량을 기존보다 6분의 1로 줄이는 ‘터보퀀트(TurboQuant)’ 기술을 공개했다. 터보퀀트 기술은 이미 1년 전 논문에서 소개된 기술이지만 최근 HBM 수요 폭발에 따른 공급난 상황과 맞물려 화제가 된 기술이다.
터보퀀트는 AI 모델이 과거 대화 내용을 기억해 다음 답변에 활용하는 임시 메모리인 ‘KV 캐시’를 압축해 효율을 극대화한다. 메모장을 예로 들면 과거에는 크게 썼던 글씨를 촘촘하게 적어 넣어 여유 공간을 확보할 수 있고, 여유 공간에 기존보다 많은 데이터를 저장할 수 있다는 이론이다. 구글 리서치에 따르면 터보퀀트는 16비트로 저장하던 KV 캐시를 3비트로 압축해주기 때문에 엔비디아 H100 대비 연산 속도는 최대 8배까지 향상될 수 있다고 소개했다.
터보퀀트가 앞으로 HBM 수요를 줄일 수 있는 기술로 인식되면서 HBM 제조사 주가가 타격을 입었다. 매튜 프린스 클라우드플레어 최고경영자(CEO)는 SNS에서 터보퀀트 기술을 “구글의 딥시크”라고 평가하며 “AI 추론 속도, 메모리 사용, 전력 소비 등에서 최적화할 여지가 훨씬 더 많다는 점을 보여준다”고 설명했다. 지난해 1월 중국 딥시크가 오픈AI 투자 비용 10분의 1도 안되는 600만 달러만 쓰고도 고성능의 ‘R1’을 출시했다는 소식이 전세계가 충격에 휩싸였을 때와 비교한 것이다.

반도체 업계가 병목을 최소화하기 위해 메모리를 연결하고, 쌓고, 압축하는 아이디어를 제시하고 있는 만큼 HBM 제조사들도 획기적인 기술을 내놓을 수 있다는 관측이 나온다. 현재 HBM이 12단을 주력으로 하는 상황에서 적층 수가 16단 이상으로 높아질 수 있지만 반도체 규격 규제와 기술적 난이도 때문에 당장 실현 가능하지는 않다.
이러한 제약 때문에 2~3년 뒤에는 HBM도 칩 위에 올리는 시도가 이뤄지지 않겠느냐는 전망이 나온다. 그록·세레브라스가 S램을 칩에 통합하는 온칩 메모리 기술로 데이터 처리 속도를 향상시킨 것과 유사한 전략이 될 수 있다. S램을 앞세우는 스타트업들과 달리 이미 적층에 성공한 HBM 제조사들 입장에서는 칩 위에 메모리를 올리는 편이 더 획기적일 수 있다.
다만 이같은 모델은 GPU·CPU 개발사와 메모리 제조사의 갑을 관계가 확실히 역전된 상황에서 실현될 수 있다. 현재는 엔비디아가 ‘베라 루빈’과 같은 시스템을 내놓으면 여기에 맞춰서 메모리가 공급되는 구조이기 때문이다. 칩 위에 메모리를 올리려면 설계부터 패키징까지 연결된 공정이 필요하기 때문에 지금처럼 대만 TSMC에 의존하는 패키징 구조에도 변화가 전제돼야 한다.

실리콘밸리=김창영 특파원 kcy@sedaily.com
Copyright © 서울경제. 무단전재 및 재배포 금지.
- 푸틴의 한 수...美 ‘앞마당’ 쿠바에 유조선 보냈다
- 李대통령 지지율 62.2%...민주 51.1%·국힘 30.6%
- “여보, 주담대 금리 또 올랐대” 커지는 이자 공포...27개월만 최고
- BTS, ‘아리랑’으로 빌보드 200 7번째 정상…英 이어 美 앨범차트도 석권
- “미분양일 때 살 걸”…‘고분양 논란’에서 ‘가성비 신축’된 이 단지 어디?
- “한국 좋아서 왔죠” ‘캡슐 호텔’ 일본인 끝내 숨져...‘벌집구조’에 스프링클러 미설치 건
- 토큰·KV캐시·터보퀀트 ‘외계어’ 쉽게 풀어드립니다…삼전·하닉 영향까지
- “미국을 또 수렁으로 몰아넣으려는 거냐”…전쟁 한 달, 여론은 트럼프에 등 돌렸다
- 호르무즈 통행료 ‘잭팟’ 기대하는 이란 “연간 150조”
- ‘김소영 레시피’ 진화할라...처방전 없어도 항우울제 직구 버젓이