삼성전자가 칼 갈고 준비한 메모리 新무기 3선 [강해령의 하이엔드 테크] <2· HBM-PIM편>

정보기술(IT) 시장에 관심 많으신 독자 여러분, 안녕하세요. 인공지능(AI) 시대가 열리면서 반도체의 모양·성능도 정말 다양하게 변하고 있죠. D램 구조 역시 각양각색으로 바뀌고 있습니다. 대표적인 제품이 고대역폭메모리(HBM)죠.
지난 1편에서는 격변의 시대를 맞이한 삼성전자 메모리 사업부가 준비 중인 차세대 D램 LLW와 GDDR에 관한 이야기를 다뤄봤는데요. 오늘은 삼성전자가 칼 갈고 준비한 메모리 3가지 가운데 마지막으로 ‘HBM-PIM’을 다뤄보려고 합니다. 삼성전자가 2월 미국에서 열린 세계적인 반도체 설계 학회 ‘ISSCC 2024’에서 발표한 내용을 토대로 구성했습니다.

우리는 이제 HBM이 무엇인지 정도는 너무나도 잘 알고 있습니다. D램을 차곡차곡 쌓고, 정보 이동 통로(I/O)를 실리콘관통전극(TSV)으로 1024개 뚫어서 결합한 칩입니다. 이 칩은 그래픽처리장치(GPU)나 AI 반도체 바로 옆에 배치되는 메모리입니다. 기존 그래픽용(GDDR) D램보다 I/O 수가 32배나 많아 대역폭이 크고 연산장치와 메모리 사이 거리도 상당히 가깝죠. 폭증하는 데이터 시대 속에 빠른 속도로 연산을 보조해야 하는 AI 시대 메모리로 제격입니다. AI 공학인들은 HBM을 두고 ‘오아시스’ 같다고 말할 정도입니다.
그럼에도 문제는 끝나지 않습니다. 지금의 GPU와 HBM을 연결하는 이 1024개의 I/O로도 여전히 병목 현상이 해결되지 않는다는 것입니다. GPU가 아무리 성능이 좋아지고, HBM 용량과 I/O의 속도을 키워도 결국 이들을 잇는 도로의 교통 체증이 쉽게 해결되지 않으니 갈증이 해결되지 않더라는 겁니다. 물리적으로 I/O수를 늘려나가는 작업 또한 정말 쉽지 않죠. HBM의 면적이 커질수 밖에 없습니다. 또 그 와중에 AI에 필요한 데이터 수는 더욱 폭발적으로 늘어나고 사람들은 AI의 속도가 더욱 빨라지길 원합니다.
그래서 공학인들은 I/O에 관한 작업 외에도 아예 HBM 기본 구조에 손을 대는 방법을 고안하기 시작합니다. 그게 바로 HBM-PIM(프로세싱 인 메모리)의 기본 구조 입니다.
프로세싱 인 메모리. 말 그대로 메모리 ‘내부에서도 연산을 하는 콘셉트의 칩’입니다.

조금 더 구체적으로 보실까요? HBM 속 각 D램 안에는 '뱅크(Bank)'라는 것이 있습니다. 뱅크는 비트를 저장하는 기억 상자(셀)들을 일정한 단위로 묶어놓은 걸 말하죠. 군대로 따지면 '사단'급 부대와 같은 건데요. HBM-PIM은 각각의 뱅크에다가 GPU 안에서 데이터를 처리하는 '산술연산장치(ALU·Arithmetic and Logic Unit)'라는 친구를 하나씩 배치한 콘셉트입니다.
그래서 다시 GPU와 HBM-PIM을 놓고 대략적 순서를 보면 연산의 이렇습니다.
①GPU가 “나 연산할 때 이러이러한 게 필요해”라는 인풋(input)을 HBM-PIM에 넣습니다.
②각 뱅크에 배치된 ALU가 연산을 시작합니다.
③PIM 장치가 없을 때는 HBM은 연산에 필요해보이는 온갖 매개변수(파라미터)들을 GPU로 던지듯이(떠넘기듯이) 전달했다면요. HBM-PIM은 뱅크 내 파라미터를 선별하거나 그것들을 활용해서 연산을 해버립니다.
④GPU가 정말 필요한 파라미터만 걸러져 전달이 되거나, 이 ALU가 아주 새롭고 신박하지만 연산에 도움이 되는 결과값을 만들어 GPU에 전달하는 거죠. 자연스럽게 정체되던 이동 통로의 교통 체증은 해소됩니다.

정리하자면 이 구조는 우리의 회사·조직 생활과 비슷합니다. 통상 상급자는 주로 업무에 필요한 자료를 처음부터 끝까지 조사하지 않죠. 각 부서에 배치된 직원들이 솎아내고 정리한 결과를 보고받아 의사결정을 합니다. HBM-PIM 속에 있는 ALU들이 회사에 있는 아주 유능한 직원들이라고 보시면 적당합니다.

AI 연산에서는 크게 데이터를 훈련(Training)을 하는 단계와 추론(Inference)의 단계로 나누고, 특히 이 추론 단계 중에서는 새롭게 무언가를 생성(Generative)하거나 식별하고 데이터를 분류하고 식별(Discriminative)하는 단계가 있죠.
HBM-PIM을 요즘 유행하는 AI, 특히 생성형 AI 분야에 이걸 적용해보면요. 특히 추론 단계 중에서도 연산한 결과값을 사용자에게 보여주는 '생성'하는 단계에서 병목 현상이 확실하게 줄어든다고 합니다.
더 가까운 예를 하나 들어볼까요. 여러분 챗GPT 해본 적 많으시죠. 만약 독자님들이 챗GPT에게 질문을 하면, 챗GPT가 어떤 반응을 보이던가요. 한 단어, 한 단어를 틈을 두고 답변을 이어가죠. 그런데 만약 HBM-PIM이 의도한대로만 작동한다면 생성 속도가 더욱 빨라져서 질문에 대해 통째로 '딱' 답변을 내놓을 수가 있을 가능성이 큽니다.

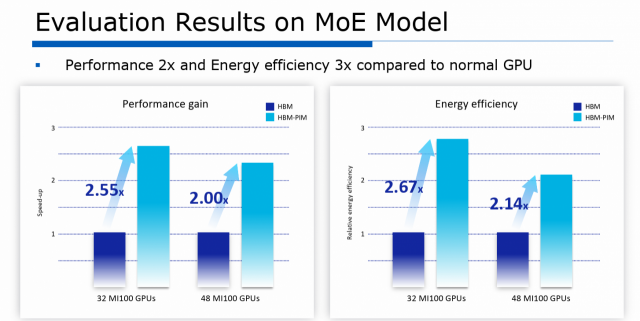

이런 HBM-PIM의 장점을 삼성전자는 ISSCC 2024에서 다양한 그래프를 통해 소개했습니다. 특히 AMD와의 HBM-PIM 공동 연구와 성과에 대한 발표가 흥미롭죠. AMD의 '32 MI100' GPU로 성능을 테스트해봤더니 기존 HBM을 썼을 때보다 GPU 성능이 2.55배나 올랐고요, 또 에너지 효율은 2.67배나 개선됐다고 강조했습니다. 또 AMD의 수장 리사 수 CEO는 한 학회의 기조연설에서 HBM-PIM을 쓸 때 기존 HBM보다 전력을 85%나 아꼈다고 말했고, 우리는 이 연구를 삼성전자와 지속하고 있다고 공식적으로 이야기하기도 했었죠.
그런데 이 PIM 기술은 말이죠. HBM 외에도 다른 애플리케이션 확장 가능성이 있습니다. 삼성은 각종 모바일 기기 속에서 아주 컴팩트하게 쓰이는 LPDDR D램에 이 기술을 접목할 수 있다고 소개했습니다.

NPU, GPU, CPU 등 연산장치 바로 옆에서 LPDDR의 성능을 한층 끌어올릴 수 있다고 주장했는데요. 특히 NPU와 LPDDR-PIM 조합의 경우, 기존 LPDDR5와의 조합보다 성능이 4배 이상이나 늘어나고 전력 소비는 71%나 감소한 멋진 역할을 해냈다고 설명했습니다.
이들의 방향대로만 된다면 PIM은 정말 혁신적인 제품이 될 수 있을 텐데요. 업계에서 PIM의 장벽 중 하나로 '공정'의 문제를 제기하는데요. 이 PIM 공정은 메모리 제조 라인에서 이뤄지게 될 확률이 크죠. 과연 메모리 제조 라인의 장비들이 D램과는 전혀 특성이 다른 연산 처리장치(ALU) 제조까지 동시에 해낼 수 있을지 볼 일입니다.
수년 전부터 HBM-PIM의 잠재력을 예의주시하고 있는 삼성이 이 작업을 해내서 많은 AI 반도체 고객사들의 선택을 받을 수 있을지도 지켜봐야겠습니다.
삼성의 ISSCC 2024 발표를 기반으로 한 차세대 메모리 3선 시리즈는 여기까지입니다. 읽어주셔서 감사합니다.
다음회는 아래 사진에 관한 건입니다. 기대해주세요!

Copyright © 서울경제. 무단전재 및 재배포 금지.
- 17억 줬는데 '또 빌려줘'…부친에 1500차례 연락한 ‘도박중독’ 아들
- 서울 오피스텔서 20대 여성 숨진 채 발견…40대 남성 용의자 긴급체포
- 계단 오르는데 가슴 찌릿? 당장 ‘이 검사’ 받아야 할 신호 [건강 팁]
- 투명투표함·인터넷차단…'표현자유' 사라진 러시아 대선
- '돼지 성폭행'하고 내던지며 학대한 남성에 호주 '발칵'…처벌 수위는?
- 홍준표, 도태우 공천 취소에 “호떡 뒤집기 판…한동훈은 셀카만”
- 난교·애마부인·대마초…'예찬대장경' 어디까지
- 유한양행 28년 만에 ‘회장직’ 부활…'글로벌 50대 제약회사로 도약'
- '너 때문에 억울하게 징역'…과도로 살인 저지른 70대 무기징역
- 민주 '현재 판세. 지역구 130~140석, 비례 13석+ 알파'