[기고] 한국이 AI반도체 개발 경쟁에서 이기는 법
(지디넷코리아=이효승 네오와인 대표)미국 엔비디아 시가총액(3996억 달러, 약 519조원)은 삼성전자(346조원) 보다 100조원 이상 많다. 삼성은 대만 TSMC보다도 시총이 훨씬 작다. 삼성은 D램, 낸드(NAND) 메모리와 휴대폰, 가전, 네트워크, 통신을 갖고도 TSMC(4374억달러, 568조원)보다 시총이 200조원 이상 적다. 왜 그럴까?
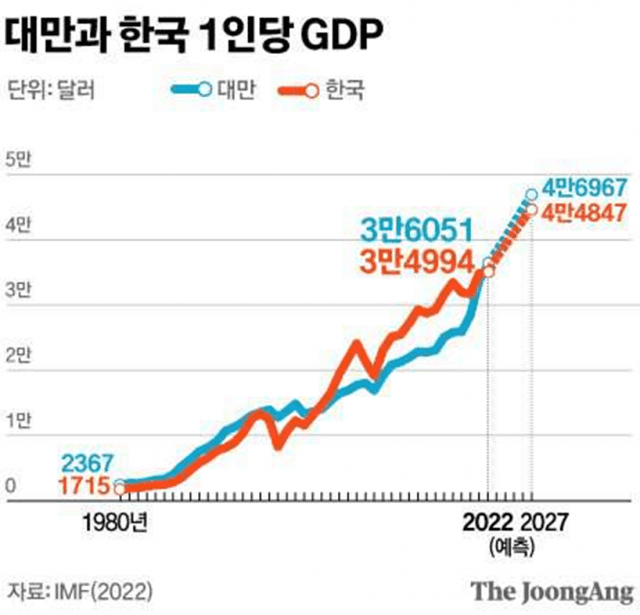
우리나라 경제는 삼성전자에 상당 부분을 의존하고 있다. 이 때문에 삼성의 파운드리 시장 경쟁력 저하는 우리 경제에도 큰 영향을 미친다. TSMC 등을 보유한 대만은 1인당 GDP도 조만간 한국을 추월할 태세다. 삼성전자가 TSMC에 비해 저평가 된 것은 상대적으로 부족한 반도체 파운드리 때문이다. 삼성전자는 TSMC 와 경쟁에서 이기기 위해 GAA(Gate All Around) 3nm 공정 셋업을 했고 양산한다고 발표했다. 그럼에도 불구하고 엔비디아, AMD, 인텔, 퀄컴, 애플 등 주요 반도체 기업은 삼성보다 TSMC를 선호하는게 사실이다. 왜 그럴까?
■ 한국 파운더리 산업의 IP 부족 문제
근본 원인은 IP 부족과 미세공정에서의 소비 전력과 속도 차이 때문이다. 그동안 삼성전자는 파운드리 산업보다 메모리 반도체 성장에 주력했다. 같은 회로 선폭의 미세공정이라도 파운드리 회사에 따라 소모전력과 동작속도 차이가 크다. 예를 들어 같은 7nm 공정에서도 같은 면적의 반도체가 3GHz 로 동작한다면 파운드리에 따라 게이트 집적도와 소모전력 차이가 발생한다. 또 같은 미세공정이라도 트랜지스터 셀의 구조에 따라 속도 차이가 발생한다. 이런 정보는 회사별로 극비 사항이기 때문에 공개적으로 발표된 자료는 찾기가 쉽지 않지만 상당수 반도체 회사가 TSMC를 선호하는 것은 종합반도체(IDM) 기업이냐 파운드리 회사이냐의 지배 구조 차이를 떠나 회로 성능 이슈가 있기 때문이다.
■국내 파운드리 산업 경쟁력이 떨어지는 이유
이런 성능 차이는 왜 발생할까? 알다시피 삼성전자는 우리나라 최고의 인재들이 모여 개발하는 회사다. 설계 인력이 부족한 탓도 있지만, 이들이 밤낮으로 열심히 개발하는데 왜 더 좋은 장비와 미세공정을 셋업 하고도 기본적인 성능에서 떨어질까? 심지어 30년전만해도 파운드리 산업은 우리나라가 대만보다 기술면에서 앞서 있었다. 그런데 지금은 왜 이렇게 됐을까? 필자가 보기엔 네트워크 효과 때문이다.
■ 파운드리와 팹리스간 상호 의존성
어떤 분들은 파운드리를 인쇄소로, 팹리스를 인쇄할 책을 쓰는 작가로 비유한다. 그런데 이 비유는 약간 맞지 않는 부분이 있다. 보통 작가는 그들끼리 자기 콘텐츠를 공유하는 일이 거의 없다. 그러나 파운드리는 다르다. 많은 회사들이 IP와 설계를 적극적으로 공유해 사용한다. 최근의 반도체는 반도체 IP 뿐만 아니라 OS 와 SW 플랫폼, SW SDK, 컴퓨터 아키텍처 등을 공유한다. 심지어 내가 설계하는 부분은 1-2% 정도고 나머지 98%는 다른 회사의 IP를 구입해 개발한다. 소설 작가가 책의 98%를 다른 작가의 작품을 글자 하나 안 바꾸고 사용하는 경우가 있는가? 하지만 팹리스 산업은 다른 회사의 IP를 비용을 지불하고 사용하는 것을 표절이라 하지 않고 오히려 권장한다. 무선 통신인 RF나 아날로그 회로 재사용은 TSMC 파운드리 내에서만 가능하다. 삼성 파운드리로 가면 회로 특성이 달라지기 때문에 몇 십번의 시험생산 과정을 거쳐 완전히 재설계 해야 한다. 디지털 회로는 그다지 바뀌지 않지만 셀 구조 변경에 따른 동작속도가 예민해 재구성하는 노력을 다시 해야 한다.
■ 파운드리 미세공정 IP 공유
최근 미세공정을 사용하는 인공지능 팹리스 반도체 회사는 LVDS, HDMI, PCIe, DDR, USB, ISP, HVC, Security 등을 필수적으로 사용한다. 이 필수적인 용도의 IP는 상당한 설계 기술과 노하우를 필요로 한다. 그래서 검증된 IP냐 FPGA 레벨에서의 동작 이냐에 따라 천지 차이로 가격이 높아진다. 파운드리는 사실 기본적으로 IP를 개발할 능력과 방법이 없다. 물론 파운드리가 자기 자본을 들여 기본적인 SRAM 과 셀, 디자인 킷을 준비하지만 이런 고속 기술을 사용한 고도의 IP는 파운드리 커스터머인 팹리스가 검증한다.
예를 들어 TSMC 파운드리의 A고객사가 테스트하고 양산에 적용한 IP라면 B사는 믿고 사용한다. 따라서 A 회사에서 양산에 적용하기 전의 IP가격이 양산이 검증된 후에는 부르는 게 값이 될 수 있다. 이런 고객이 수백, 수천개 있는 것이 바로 TSMC의 경쟁력이다.
이런 IP 경쟁력이 다시 고객사에 홍보되고 모여든 고객사가 파운드리 경쟁력을 높여주는 부익부 빈익빈 효과가 파운드리간 경쟁에서 심화하고 있다. 이런 부익부 빈익빈 효과는 반도체 수율 개선, IP 설계와 검증, 트랜지스터 구조 개선, 반도체 화합물 레시피, 장비운용, 각종 자재 구입에 영향을 미치기 때문에 파운드리가 양산에 경쟁력 있게 성장하기 위해서는 수많 고객사의 기여가 필수적이다.
■ 한국 SoC 산업의 위기와 기회
이런 상황에서 연간 30조원의 국가 연구개발비를 관리하는 정부는 어떻게 해야 민간기업의 경쟁력을 높일 수 있을까? 필자가 보기에 그 답은 인공지능 반도체 개발에 있다. 인공지능 반도체는 그야말로 뇌의 뉴런과 시냅스에 해당하는 텐서가 얼마나 많이 있는가에 따라 성능이 달라지기 때문에 엄청난 집적도가 필요하고 또한 미세공정이 매우 중요하다. 그런데 최첨단 공정인 3nm를 사용하기 위해서는 IP개발과 설계 부분에 상당한 기간과 많은 비용의 투자가 장기간 지속돼야 한다. 이러한 투자를 국내 팹리스와 대학교, 출연연구소 등이 공동으로 협력해 셋업하면 어떨까 한다.
■ 인공지능 SW 개발 환경
사실 인공지능 반도체보다 더 중요한 것은 SW 플랫폼 기술 개발이다. 젠슨 황 CEO가 말하기를 엔비디아는 반도체 회사가 아니고 소프트웨어 회사라고 했다. 인공지능 반도체는 인공지능 모델과 컴파일러 환경이 없으면 무용지물이다. 엔비디아 GPU는 '쿠다(CUDA)'라는 플랫폼을 갖고 있기 때문에 가치가 있는 것이다. 구글의 텐서플로(TensorFlow)도 구글 반도체가 좋아 사용하는 것이 아니고 SW 컴파일 환경과 그에 따른 사용자가 많기 때문이다. 반도체 개발자나 SW모델 개발자는 사실 컴파일러 존재를 자세히 모른다. 프로그램 개발자가 항상 사용하면서도 너무나 자연스럽고 쉽게 사용하고 있기 때문이다. 마치 존재를 모르는 공기와 같은 것이 SW 컴파일러다.
■ 국내 인공지능 컴파일러 개발환경
다행스럽게도 우리나라 몇몇 회사는 인공지능 컴파일러를 국내 유수한 대학과 출연연구소와 같이 개발했다. SW 컴파일러 개발의 문제점은 이 기술을 판매할 수 없다는 것이다. 인공지능 반도체를 판매하기 위해 꼭 필요한 기술이지만 사실 컴파일러는 여러 종류의 NPU 반도체에도 적용할 수 있기 때문에 일반적인 팹리스 회사는 당장 물리적으로 보이는 NPU 개발에 많은 비용을 사용한다. 그런데 정작 인공지능 반도체를 개발해 양산하려면 인공지능 반도체 고객은 사용할 인공지능 모델이나 관련 SW SDK(소프트웨어 개발 키트)가 없기 때문에 양산과 판매를 못하게 된다.
이런 상황을 방지하기 위해 인공지능 반도체가 개발되기 전에 인공지능 프로그램과 파이토치(Pytorch), 텐서플로(TensorFlow) 같은 인공지능 플랫폼의 AI 모델을 그대로 번역해 사용하기 위한 컴파일러 기술이 선행돼야 한다. 엔비디아는 물론 ARM, 구글 등 모든 세계적으로 유명한 인공지능 회사는 자체 컴파일러를 보유하고 있다. 한국에서는 그간 컴파일러 기술을 개발한 인력이 드물기 때문에 한국의 인공지능 반도체 회사들이 공유할 수 있는 공개 컴파일러를 공동으로 개발해야 한다.
■ 인공지능 회사간 차별화 문제
그런데 여기서 문제가 발생하게 된다. 미세공정 NPU 반도체를 공유해 개발하면 HW 플랫폼을 공유할 수 있어 속도와 안정성, 개발 비용이 100분의1로 감소하는 건 분명하다. 그런데 SW 컴파일러, SW SDK까지 공유한다면 인공지능 반도체 회사의 차별성은 어디서 찾을 수 있을까?
필자는 그것을 다양한 인공지능 반도체 솔루션에서 찾아야 한다고 생각한다. 중국 반도체는 특유의 가성비를 가지고 있는데 그 가성비는 중국 정부가 수백조원의 지원을 하고 있기 때문이다. 일반적인 인공지능 반도체 구조는 거의 대동소이 하다. LVDS, HDMI, PCIe, DDR, USB, ISP, HVC, Security에 카메라 입력과 멀티미디어 기능, AI NPU에서 신호처리를 하고 낸드 플래시(NAND flash) 인터페이스를 갖고 있다. CPU코어도 대개 쿼드 코어(Quad Core)의 ARM 이나 RISC-V를 탑재하고 있다. 이런 반도체를 3nm로 개발한다면 엄청난 개발비가 소요된다. 그런데 이렇게 개발된 반도체는 AI 서버용 GPU, AI IP 카메라, AI CCTV, AI IoT, AI 드론, AI 로봇 등 많은 설계 부분에 공통적으로 사용할 수 있으며, 경우에 따라 그대로 양산할 수도 있다. 내부 OS는 거의 리눅스가 될 것이다.
우리나라의 많은 NPU 회사들은 엄청난 검증 및 IP 사용, MPW, 싱글 런 개발비용 때문에 삼성전자의 3nm 미세공정 프로세스를 사용하는 것은 엄두도 못내고 있다. 차제에 SW, HW 공통 플랫폼을 기획하고 제품과 상품의 차별화는 솔루션에서 만들어 내면 어떨까 한다. 공개 소프트웨어, 하드웨어 플랫폼은 개발비와 개발시간, 인건비, MPW 테스트 횟수가 엄청난데 비해 소유권이 애매해 자체 매출을 올리기 쉽지 않다. 그러나 이런 플랫폼이 개발돼 삼성전자의 미세공정이 셋업 되면 경쟁력을 갖게 되고 또 인공지능 반도체 회사들도 경쟁력을 갖는다.
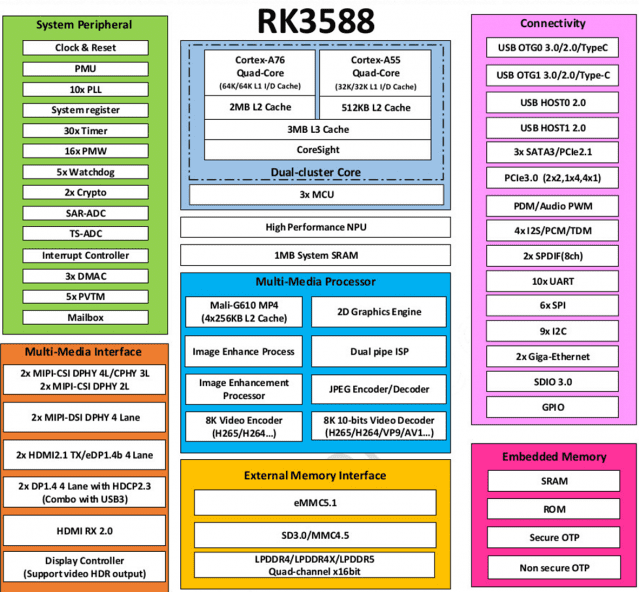
우리가 개발하려는 반도체는 이미 중국회사들이 선점하고 있다. 중국에서 양산하고 있는 락칩(Rockchip)을 보면 이미 우리 인공지능 반도체 회사가 개발하려는 부분이 완성돼 판매되고 있다.
■ 국내 인공지능 반도체가 갖는 무게
차제에 14, 5, 3nm 미세공정에서 공동으로 기회를 찾고 AI 솔루션으로 매출을 만들어야 하지 않을까 한다. 이런 솔루션은 HW 의존성이 엄청나 AI 반도체 회사만 만들 수 있다. 약간의 스펙이라도 바뀌면 합의하에 반도체 내부 회로와 구조, SW 드라이버, SW 디자인킷, 컴파일러 등을 뒤집는 것을 일반적인 소프트웨어 개발자는 생각할 수 없다. 자동차와 철강, 조선, 메모리로 성장한 우리나라 경제와 운명이 절체절명인 상황에서 인공지능 반도체 국산화와 성능 이슈는 절박하다. 과거의 방법대로 개발하면, 변화하지 않으면, 모두가 망할 수 밖에 없다.

이효승 네오와인 대표(godinus@neowine.com)
Copyright © 지디넷코리아. 무단전재 및 재배포 금지.
- 다이가 다르다...삼성·SK, 차세대 HBM '두뇌' 로직다이서 엇갈린 전략
- 배경훈 부총리 "중동 AI 협력 활발…비대면 회의 앞둬"
- 과열 대신 차분…배터리 3사 CEO 빠진 인터배터리 첫날
- 비용은 한국이, 이익은 넷플릭스가?...BTS 광화문 생중계 명과 암
- 이준희 대표, 첫 연봉 9억8000만원…삼성SDS 연봉 1위는
- 메타, AI만의 SNS '몰트북' 인수…차세대 생태계 선점
- IEA 비축유 방출 제안했더니…금값 5200달러 돌파
- [현장] 둘다 보급형인데…아이폰17e보다 '맥북 네오'에 쏠린 눈
- '각형' K배터리 원조 삼성SDI "특허 침해 좌시 않을 것"
- 애플, 플립형 폴더블폰 검토하다 접었다…왜?