< Science >얼굴표정으로 내 감정 읽은 AI, 딱 맞는 여행지·음악 골라준다
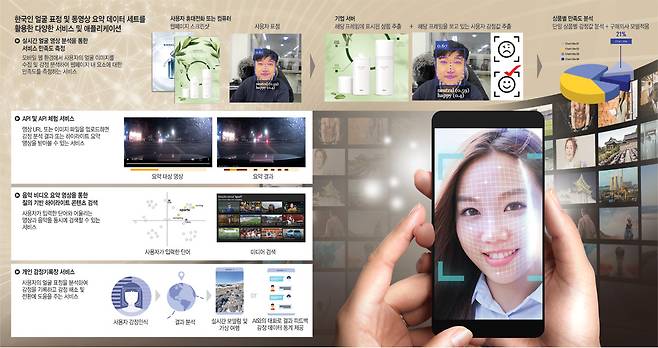
■ 카이스트 연구팀, 감정인식·음악검색 AI기술 개발
한국인 얼굴사진 50만장 기반
기쁨·불안 등 7가지로 수치화
복합 감정땐 그러데이션 활용
유튜브 동영상을 음악과 연계
장르·기분·상황·악기별 분류
검색창에 입력땐 바로 찾아줘
실연으로 상처받고 우울할 때 인공지능(AI)이 주인의 표정을 알아차리고 겨울 바닷가 같은 힐링 여행장소를 추천해준다면 어떨까. 광고 CF 감독이 차량 추격장면을 구상하면서 참고할 영화 영상이나 삽입 음악을 찾으려 며칠 밤을 새우고 있을 때 AI가 찰떡궁합 영상과 음악을 딱 찾아준다면 어떨까.
둘 다 순수 우리나라 기술로 거의 완성단계에 이른 감정인식 AI와 영상·음악 검색 AI가 실제로 해줄 수 있는 서비스다. 카이스트 문화기술대학원 박주용·남주한·이원재 교수팀은 아트센터 나비, 미디어테크아트업체 리콘랩스와 손잡고 사람의 감정을 읽어 그 상태에 딱 맞는 여행 등 서비스 상품을 제안하거나, 유튜브 같은 방대한 분량의 영상자료를 검색, 원하는 영상과 음악을 신속하게 찾아주는 국내 기술을 완성해 최근 온라인으로 시연행사를 열었다. 앞으로 기업의 마케팅 업무나 광고·미디어 업종 종사자들의 신상품 개발과 자료조사에 드는 시간 및 비용을 크게 절약해줄 수 있을 것으로 기대된다.
◇감정도 읽고 서비스하는 AI = 먼저, 감정인식 AI의 경우 개발 전 단계로 총 50만 장의 한국인 얼굴 사진 자료에 기반해 기쁨·불안·분노·당황·상처·슬픔·중립 등 국제적으로 통용되는 7가지 감정 영역으로 분류한 다음 이를 수치화했다. 또 기쁨과 당황이 섞이는 등 복합적 감정을 표현하기 위해 시각적 그러데이션(gradation·점진적 이행) 기법을 활용해 여러 색채가 섞여 있는 모습으로 결과가 나오도록 했다.
개발에 참여한 AI 전문기업 액션파워 관계자는 10일 “한국인의 얼굴 표정에 가장 맞도록 정합성을 높이는 게 관건이었다”며 “이미지 처리에 널리 쓰이는 합성곱 신경망(CNN) AI 테크닉으로 파라미터(가중치)를 정밀하게 설정하는 데 주력했다”고 밝혔다.
시연 당일에는 카이스트에서 개발한 사람 감정인식 AI 원더(Wander)가 스마트폰 사용자의 얼굴 표정에 나타난 감정을 읽어 적합한 가상(virtual) 여행 상품을 제안하는 서비스 발표가 이뤄졌다. AI 챗봇과 대화하면서 원하는 여행 상품을 더 잘 찾을 수 있도록 보완하는 아이디어도 나왔다.
카이스트 측은 또 모바일 웹상에서 사용자의 얼굴 표정에 나타난 감정을 분석해 웹페이지에 대한 만족도를 측정하는 서비스도 선보일 예정이다. 만약 이 기술이 완성되면 시간과 비용이 많이 드는 기존의 설문조사나 소수 패널 방식의 조사 대신 자동 감정 분석을 통해 상품 선호도를 실시간으로 측정할 수 있을 것으로 보인다.
◇맞춤형 영상·음악 검색도 쉽게 = 영상 및 음악 검색 AI는 마치 네이버나 구글로 키워드를 쳐서 원하는 이미지·텍스트 등을 찾아내듯, 어울리는 요약 영상 클립과 음악까지 한꺼번에 검색하는 강력한 기능을 선보여 이목을 끌었다.
사용자가 검색창에 단어를 입력하면 어울리는 영상과 음악을 동시에 찾아주는 자연어 기반의 심층 유사성 검색(Deep similarity search) 서비스다. AI를 학습시키기 위해 전문업체가 유튜브 기준으로 1000회 이상 조회된 동영상 가운데 2분 이상 60분 이하의 총 4000개, 총 1000시간 이상의 데이터를 우선 수집했다. 이를 분류하는 사람 10명 이상이 3초 간격으로 구분된 동영상에 3개 이하의 키워드로 설명을 달았다.
도승헌 카이스트 박사과정 대학원생은 “업체로부터 넘겨받은 동영상에 대해 어울리는 음악과 매칭할 수 있도록 영상을 알기 쉽게 분류하는 작업이 또 한 번 필요해서 심층 분류(deep classification) 학습 방식으로 비디오 데이터 세트에서 검출한 하이라이트 영상에 동작 설명 꼬리표를 붙였다”며 “이것을 음악에 달린 분류 꼬리표와 가장 근접하도록 벡터 공간에 분포시키는 것이 주된 과제였다”고 설명했다.
음악 꼬리표는 팝·재즈·힙합 등 장르별로, 우울·쾌활·차분 등 무드별로, 기타·피아노·드럼 등 악기별로, 달릴 때·휴식할 때·공부할 때 등 상황별로 세밀하게 나눠 붙였다. 매칭 정확도를 높이기 위해 음악의 제목과 가수 이름 등도 추가 학습 자료로 쓰였다.
노성열 기자 nosr@munhwa.com
[ 문화닷컴 | 네이버 뉴스 채널 구독 | 모바일 웹 | 슬기로운 문화생활 ]
[Copyrightⓒmunhwa.com '대한민국 오후를 여는 유일석간 문화일보' 무단 전재 및 재배포 금지(구독신청:02)3701-5555 / 모바일 웹:m.munhwa.com)]
Copyright © 문화일보. 무단전재 및 재배포 금지.